
Metadaten bei GlusterFS
Ein besonderes Merkmal von GlusterFS ist die Behandlung der Metadaten. Kenner der Szene wissen, dass hier oft eine Leistungsbremse liegt. Dies ist übrigens kein Phänomen von verteilten Datenablagen. Auch lokale Dateisystem wie Ext3, Ext4 oder XFS haben hier schon Lehrgeld zahlen müssen. Typisch für verteilte Dateisysteme ist die Implementierung dedizierter Metadaten-Instanzen. Diese versucht man dann möglichst performant und skalierbar aufzubauen, damit hier kein Engpass entsteht.
GlusterFS geht einen komplett anderen Weg und verzichtet vollständig auf Metadaten-Server. Damit das funktioniert, müssen natürlich andere Mechanismen her.
Man kann die Metadaten grob in zwei Kategorien aufteilen. Das sind zum einen Informationen, die auch ein normales Dateisystem verwaltet: Zugriffsrechte, Zeitstempel, Größe. Da GlusterFS auf Dateibasis funktioniert, kann es hier größtenteils das Backend-Dateisystem benutzen. Die eben genannten Informationen liegen dort ebenfalls vor und benötigen oft keine separate Verwaltung auf der GlusterFS-Ebene.
Die Natur von verteilten Storage-Systemen erfordert aber zum anderen weitere Metadaten. Ganz wichtig ist die Info, auf welchem Server/Brick die Daten denn nun liegen. Dies ist insbesondere dann wichtig, wenn sogenannte Distributed Volumes zum Einsatz kommen. Hier sind die Daten über mehrere Bricks verteilt. Der Anwender sieht nichts davon, für ihn sieht es wie ein einziges Verzeichnis aus. Für diese Metadaten benutzt GlusterFS teilweise ebenfalls das Backend-Dateisystem – genau genommen die erweiterten Attribute von Dateien ( Abbildung 3 ). Für den Rest speichert GlusterFS einfach gar nichts ab. Vielmehr berechnet es die notwendigen Informationen einfach.
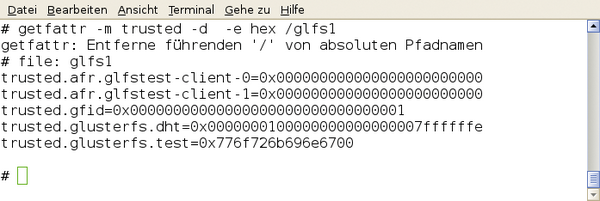 Abbildung 3: GlusterFS benutzt die erweiterten Attribute des Backend-Dateisystem zum Ablegen von Metadaten.
Abbildung 3: GlusterFS benutzt die erweiterten Attribute des Backend-Dateisystem zum Ablegen von Metadaten.
Der sogenannte Elastische Hash-Algorithmus ist die Basis dieser Berechnung. Jeder Datei ist aufgrund ihres Namens und Pfades ein Hash-Wert zugeordnet. Der Namensraum ist dann bezüglich der möglichen Hash-Werte partitioniert. Den einzelnen Bereichen werden Bricks zugewiesen.
Diese Lösung klingt sehr elegant, hat aber auch ihre Nachteile. Ändert sich der Name einer Datei, ändert sich auch der Hash-Wert. Das kann dazu führen, dass nun ein anderer Server für sie zuständig ist. Die Konsequenz des Umbenennens ist eine Kopier-Aktion der entsprechenden Daten. Legt der Anwender viele Dateien mit ähnlichen Namen in GlusterFS ab, kann es durchaus sein, dass diese alle auf dem gleichen Brick landen. Im Endeffekt kann es dann vorkommen, dass im Volume an sich noch Platz ist, aber eine der zuständigen Bricks voll ist. Frühere GlusterFS-Versionen waren dann ratlos. Inzwischen kann die Software aber solche Anfragen auf alternative Bricks weiterleiten. Ein assymmetrisch gefüllter Namensraum ist somit kein Problem mehr.
Ceph-Wachstum
Hält man sich die Geschichte von Ceph vor Augen, dann erscheinen so manche Ereignisse seltsam. Ursprünglich ging Ceph nicht als universeller Objektspeicher an den Start, sondern war darauf ausgelegt, ein POSIX-kompatibles Dateisystem zu sein – aber mit dem Clou, dass das Dateisystem auf verschiedene Rechner aufgeteilt sein sollte, also ein typisches Distributed Filesystem. Groß geworden ist Ceph in dem Augenblick, in dem die Entwickler merkten, dass sich mit dem für das Dateisystem angelegten Unterbau auch andere Speicherdienste ganz hervorragend anbieten lassen. Doch weil das gesamte Projekt stets unter dem Namen des Dateisystems firmierte und jeder Ceph kannte, entschied man sich kurzerhand, Ceph als Projektnamen zu nutzen und das eigentliche Dateisystem umzubenennen. Es gehört bis heute fix als Bestandteil zu Ceph, und heißt nun etwas sperrig CephFS (obgleich im Kernel das passende CephFS-Modul noch immer
»ceph.ko«
heißt – bis die Namen einheitlich in Verwendung sind, dürfte also noch ein Quäntchen Zeit vergehen).
CephFS bietet Nutzern den Zugriff auf einen Ceph-Cluster, als handele es sich bei diesem um ein POSIX-kompatibles Dateisystem. Für den Admin sieht der Zugriff auf CephFS genauso aus wie ein Zugriff auf ein anderes Dateisystem, im Hintergrund kommuniziert der CephFS-Treiber des Clients jedoch mit einem Ceph-Cluster und legt darin Daten ab.
Weil das Dateisystem POSIX-kompatibel ist, funktionieren alle Werkzeuge auf CephFS, die sonst auf einem normalen Dateisystem funktionieren. Die Eigenschaft der verteilten Datenablage erwächst CephFS direkt aus den Funktionen des Objektspeichers selbst, also Ceph – wichtig ist bei CephFS aber auch noch, dass es ganz im Stile eines Shared Filesystems den parallelen Zugriff von mehreren Clients ermöglicht; laut Sage Weil, Gründer und CTO von Inktank, war das eine der großen Herausforderungen beim Entwickeln von CephFS: POSIX zu beachten und ordentliches Locking zu garantieren, während verschiedene Clients gleichzeitig auf das Dateisystem zugreifen.
Um das Problem zu lösen, kommt bei CephFS der
»MDS«
ins Spiel. Die Abkürzung steht dabei für
»Metadata Server«
. Der MDS in Ceph ist verantwortlich dafür, die POSIX-Metadaten von Objekten auszulesen und quasi als riesigen Cache bereitzuhalten. Das ist ein ganz wesentlicher Design-Unterschied zu Lustre, das auch einen Metadata-Server kennt, der jedoch quasi eine riesige Datenbank ist, in der der Lageort von Objekten verzeichnet ist. Ein Metadaten-Server in CephFS greift lediglich auf die ohnehin in den User Extended Attributes der Ceph-Objekte gespeicherten POSIX-Informationen zurück und liefert diese an CephFS-Clients aus. Auf Wunsch können sogar mehrere Metadata-Server zusammenarbeiten, die einzelne Zweige eines Dateisystems abdecken. Über die Monitoring-Server erhalten die Clients in diesem Fall eine Liste aller MDS, anhand derer sie feststellen können, welchen MDS sie für spezifische Informationen kontaktieren müssen.
Der Linux-Kernel liefert einen Treiber für CephFS ab Werk mit, auch ein FUSE-Modul steht zur Verfügung, das maßgeblich auf Unix-oiden Systemen zum Einsatz kommt, die zwar FUSE können, aber eben keinen nativen CephFS-Client haben.
Der große Pferdefuß an CephFS ist im Augenblick noch die Tatsache, dass Inktank Ceph noch als Beta einstuft; die Komponente ist für den Produktiveinsatz also noch nicht ausgereift. Laut diverser Aussagen von Sage Weil ist jedenfalls dann nicht mit Problemen zu rechnen, wenn nur ein Metadaten-Server vorhanden ist. Echte Kopfschmerzen bereiten Weil und seinem Team derzeit Probleme rund um das Metadaten-Partitioning.
Das schon erwähnte Unified-Storage-Konzept von Ceph schlägt sich im Alltag des Admins besonders dann nieder, wenn es um das Skalieren eines Clusters in die Breite geht. Typische Ceph-Cluster werden wachsen, dafür ist in Ceph entsprechende Funktionalität vorhanden: Das Einbauen neuer OSDs im laufenden Betrieb ist kein Problem. Gleiches gilt übrigens auch für das Verkleinern eines Clusters. Die OSDs sind in beiden Fällen dafür verantwortlich, zusammen mit den MONs den Cluster im Hintergrund konsistent zu halten, während Benutzer stets den Cluster verwenden, nie jedoch einzelne, spezifische OSDs. Ein 20-Terabyte-Cluster wächst im Anschluss an das Eintragen neuer Festplatten in die Konfigurationsdatei des CRUSH-Algorithmus (das ist der interne Scheduling-Mechanismus von Ceph) um die entsprechende Größe an oder schrumpft entsprechend – davon ist am Frontend insgesamt jedoch nichts zu bemerken.
Ähnliche Artikel
-
GlusterFS einrichten und nutzen

-
Storage-Pools mit GlusterFS aufbauen

-
Das verteilte Dateisystem GlusterFS aufsetzen und verwalten

-
GlusterFS 3.7 für CentOS 6 und 7 verfügbar
Die Storage-Arbeitsgruppe von CentOS hat das aktuelle GlusterFS-Release gebrauchsfertig paketiert.
-
Red Hat Storage One basiert auf GlusterFS
Neben Ceph Storage bietet Red Hat jetzt auch ein auf GlusterFS basierendes Storage-Produkt an.
Konfigurationsmanagement

Themen


