
Erweiterbarkeit bei GlusterFS
Eine selbstgestellte Herausforderung der GlusterFS-Entwickler war die einfache Verwaltung und Erweiterbarkeit. Insbesondere Letzteres sollte nicht die üblichen Kopfschmerzen bereiten. Und tatsächlich, die Bedingungen sind gut. Das Hinzufügen neuer Bricks oder gar neuer Server in den GlusterFS-Pool gestaltet sich sehr einfach. Das schon mehrfach erwähnte Vertrauensverhältnis kann der neue Server aber nicht selbst aufbauen – die Kontaktaufnahme muss von einem schon integrierten GlusterFS-Mitglied kommen. Analoges gilt für den umgekehrten Fall, also wenn der GlusterFS-Verbund kleiner werden soll. Das Vergrößern und Verkleinern von Volumes ist auch nicht weiter schwierig, aber es gilt ein paar Dinge zu beachten.
Die Anzahl der Bricks muss zum Setup des Volumes passen, insbesondere, wenn Replikation im Spiel ist. Bei einem Kopierfaktor von 3 erlaubt GlusterFS nur eine Erweiterung um
»n«
"Ziegelsteine", wenn
»n«
durch drei teilbar ist. Dies gilt auch beim Entfernen von Bricks. Ist das Volume replizierend und verteilt, dann wird es etwas knifflig. Nun muss der Admin aufpassen, dass die Reihenfolge der Bricks passt. Sonst laufen Replikation und Verteilung kreuz und quer. Leider ist hier die Verwaltungsschnittstelle nicht sehr hilfreich. Ändert sich die Anzahl der Bricks, ändert sich auch die Partitionierung des Namensraums. Für neue Dateien gilt dies automatisch. Existierende Dateien, die nun eigentlich woanders liegen müssten, wandern aber nicht automatisch an die richtige Stelle. Hier muss der Admin den Prozess
»rebalance«
anschieben. Der richtige Zeitpunkt dafür hängt von verschiedenen Gegebenheiten ab: Wieviele Daten sind zu migireren? Ist die Client-Server-Kommunikation betroffen? Wie heiß laufen die alten Rechner? Einen richtig guten Daumenwert gibt es leider nicht. Hier muss jeder GlusterFS-Admin seine eigenen Erfahrungen sammeln.
Ausfallsicher durch Kopieren und Verteilen
Ein wesentlicher Aspekt für die Hochverfügbarkeit der Daten in verteilten Storage-Lösungen ist die Anfertigung von Kopien. In der GlusterFS-Sprache nennt sich das Replikation – und ja, es gibt einen Translator dafür. Es ist dabei der Paranoia des Admins überlassen, wieviele Kopien er automatisch anfertigen lässt.
Die Grundregel ist, dass die Anzahl der verwendeten Bricks ein ganzzahliges Vielfaches des Replikationsfaktors sein muss. Dies hat übrigens auch Konsequenzen für das konkrete Vorgehen beim Wachsen oder Schrumpfen des GlusterFS-Verbundes – doch dazu später mehr. Die Replikation erfolgt automatisch und quasi-transparent für den Benutzer. Die Anzahl der gewünschten Kopien setzt man per Volume fest. Es ist also möglich, dass vollkommen unterschiedliche Replikationsfaktoren in einem GlusterFS-Verbund vorliegen. Prinzipiell kann GlusterFS entweder TCP oder RDMA als Transport-Protokoll verwenden. Letzterem sollte der Vorzug gegeben werden, wenn es auf niedrige Latenzen ankommt.
Realistisch gesehen spielt RDMA aber eher eine Außenseiterrolle. Wo der Replikationsverkehr stattfindet, hängt von der Zugriffsart des Clients ab. Kommt der native GlusterFS-Dateisystemtreiber zum Einsatz, dann kümmert sich der sendende Rechner darum, dass die Daten zu allen notwendigen Bricks gehen. Dabei spielt es keine Rolle, welchen GlusterFS-Server der Client beim Mounten anspricht. Im Hintergrund baut die Software die Verbindung zu den eigentlichen Bricks auf.
Beim Zugriff über NFS regelt GlusterFS das intern. Entsprechend konfiguriert muss der Client-Server-Kanal nicht auch noch den Kopierdatenstrom mitverarbeiten. Eine besonderes Schmankerl ist die sogenannte Geo-Replikation. Hierbei handelt es sich um eine asynchrone Replikation zu einem weiteren Rechenzentrum (Abbildung 4). Das Setup ist einfach und beruht im Wesentlichen auf
»rsync«
über SSH. Es spielt keine Rolle, ob auf der Gegenseite auch ein GlusterFS-Verbund steht oder nur ein normales Verzeichnis.
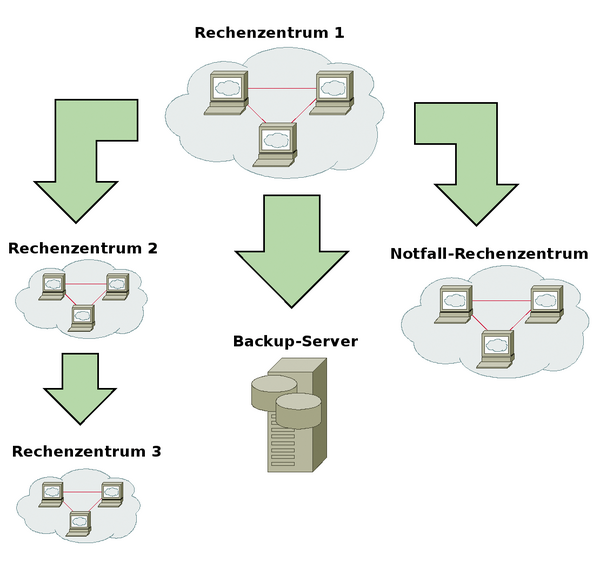 Abbildung 4: Geo-Replikation ist mit GlusterFS ganz einfach – skaliert aber nicht besonders gut.
Abbildung 4: Geo-Replikation ist mit GlusterFS ganz einfach – skaliert aber nicht besonders gut.
Zum gegenwärtigen Zeitpunkt ist die Geo-Replikation ein serieller Prozess und leidet an den von
»rsync«
bekannten Skalierungsproblemen. Außerdem läuft der Prozess auf der Zielseite in der Standardkonfiguration mit Root-Rechten und stellt damit ein gewisses Sicherheitsrisiko dar. Mit Version 3.5 soll eine komplett überarbeitete Version kommen. Die Replikation ist dann parallelisierbar. Das Erkennen, welche Veränderungen vorliegen und damit Teil des Kopiervorgangs sind, soll ebenfalls deutlich schneller und performanter sein.
Für ein replizierendes Volume ist der Ausfall eines Bricks an sich für den Anwender transparent – wenn es sich nicht um den letzten verbliebenen handelt. Der Benutzer kann weiterarbeiten, während die Prozeduren zur Reperatur ablaufen. Nach getaner Arbeit kann GlusterFS den Brick wieder integrieren und startet automatisch den Datenabgleich. Ist der Brick aber nicht reparierbar, dann ist Handarbeit angesagt. Der Admin muss ihn aus dem GlusterFS-Verbund herauskonfigurieren und einen neuen einbinden. Zum Schluss erfolgt dann der Abgleich der Daten, damit wieder die gewünschte Anzahl von Kopien vorhanden ist. Aus diesem Grund empfiehlt sich für die einzelnen Bricks eine gewisse Ausfallsicherheit außerhalb von GlusterFS zu implementieren. Mögliche Maßnahmen wären der Einsatz von RAID-Kontrollern und/oder redundante Netzteile und Schnittstellenkarten.
Greifen Anwender und Applikation über NFS auf GlusterFS zu, müssen weitere Maßnahmen her. Der Client-Rechner hat hier nur eine Verbindung zu einem NFS-Server. Fällt dieser aus, ist der Zugriff auf die Daten erstmal weg. Der empfohlene Weg ist das Aufsetzen einer virtuellen IP, die im Fehlerfall auf einen funktionierenden NFS-Server umspringt. In seinem kommerziellen Produkt verwendet Red Hat die aus der Samba-Welt bekannte Cluster Trivial Data Base (CTDB, [9] ).
Wie bereits eingangs erwähnt gehen die beteiligten Server im GlusterFS-Verbund ein Vertrauensverhältnis ein. Für alle verteilten Netzwerk-basierten Dienste stellt der Ausfall von Switchen, Routern, Kabeln oder Schnittstellenkarten ein gewisses Ärgernis dar. Ist der GlusterFS-Verbund durch so einen Vorfall geteilt, stellt sich die Frage, wer nun schreiben darf und wer nicht. Ohne weitere Maßnahmen verwandelt sich die ungewollte Partitionierung auf Netzwerkebene in einen Daten-GAU durch Split Brain. Seit Version 3.3 beherrscht GlusterFS Quorum-Mechanismen. Der GlusterFS-Server kann im Fall einer Kommunikationsstörung entscheiden, ob der Brick noch schreiben darf oder nicht. Das Setup ist dabei recht einfach. Man kann das Quorum komplett abschalten, auf Automatik setzen oder die Anzahl der Bricks einstellen, die als Mehrheit gelten sollen. Bei der Automatik gilt das Quorum, wenn mehr als die Hälfte der beteiligten "Ziegelsteine" noch funktionieren.
Ähnliche Artikel
-
GlusterFS einrichten und nutzen

-
Storage-Pools mit GlusterFS aufbauen

-
Das verteilte Dateisystem GlusterFS aufsetzen und verwalten

-
GlusterFS 3.7 für CentOS 6 und 7 verfügbar
Die Storage-Arbeitsgruppe von CentOS hat das aktuelle GlusterFS-Release gebrauchsfertig paketiert.
-
Red Hat Storage One basiert auf GlusterFS
Neben Ceph Storage bietet Red Hat jetzt auch ein auf GlusterFS basierendes Storage-Produkt an.
Konfigurationsmanagement

Themen


