
Loadbalancer-Lösungen
Die Grundidee eines solchen Web-Loadbalancers ist simpel: Eine Software lauscht auf einem System auf der Adresse und auf dem Port, der eigentlich zur Anwendung gehört. Das ist der Loadbalancer. Im Hintergrund existieren die sogenannten Backend-Server, also die eigentlichen Webserver. Der Loadbalancer nimmt eingehende Verbindungen an und verteilt sie nach einem festen Modus auf die Backend-Server. So ist für eine gleichmäßige Auslastung gesorgt, und obendrein gibt es kein System, das nichts tut.
Neben den Software-basierten Loadbalancern, mit denen sich dieser Artikel maßgeblich beschäftigt, sind die Loadbalancer-Appliances mittlerweile sehr beliebt, weil sie fix und fertig vom Hersteller kommen und nur noch ein Mindestmaß an Konfiguration benötigen. Spannender ist allerdings ein Überblick über die Software-Implementationen, die für Linux zur Verfügung stehen.
Mit Loadbalancern ist es so ein bisschen wie mit Identd-Daemons oder IRC-Servern: Für praktisch jeden Geschmack ist etwas dabei. Wer aus der Netzwerk-Ecke kommt, wird an
»ldirectord«
[2]
Gefallen finden, denn es handelt sich nicht nur um einen der erprobtesten Loadbalancer für Linux, sondern außerdem um eine der wenigen Implementierungen, die auf IPVS aufbaut und direkt im Kernel ansetzt.
Als Alternative gelten solche Loadbalancer, die komplett im Userspace beheimatet sind; der prominenteste Vertreter dieser Art ist zweifelsohne HAProxy ( Abbildung 3 ), mit dem sich in kürzester Zeit ebenfalls Loadbalancer-Setups aus der Taufe heben lassen. Das Listing 1 zeigt eine beispielhafte Konfiguration für HAProxy (/etc/haproxy/haproxy.cfg), die bereits SSL unterstützt und eingehende Requests auf Port 80 auf drei verschiedene Backend-Server weiterleitet.
Listing 1
haproxy.cfg
 Abbildung 3: Jeder Dienst in OpenStack kommt mit einer API daher. Im Beispiel zu sehen sind die RESTful-APIs von Nova, Cinder, Glance und Quantum sowie Keystone, das selbst ausschließlich eine RESTful-API ist.
Abbildung 3: Jeder Dienst in OpenStack kommt mit einer API daher. Im Beispiel zu sehen sind die RESTful-APIs von Nova, Cinder, Glance und Quantum sowie Keystone, das selbst ausschließlich eine RESTful-API ist.
Sind die Backend-Server so konfiguriert, dass auf jedem der Computer ein Webserver oder ein RESTful-Dienst lauscht, bildet das Gespann aus HAProxy und jenen Backend-Servern bereits ein komplettes Setup. Es hängt insofern nicht davon ab, ob der RESTful-Dienst selbst einen Webserver als externen Dienst braucht, wie es beispielsweise beim Rados-Gateway der Fall ist, das zu Ceph gehört, oder ob der Dienst selbst auf einem Port lauscht, wie im OpenStack-Beispiel, bei dem sämtliche API-Dienste die Kontrolle über den HTTP- oder HTTPS-Port selbst übernehmen ( Abbildung 2 ).
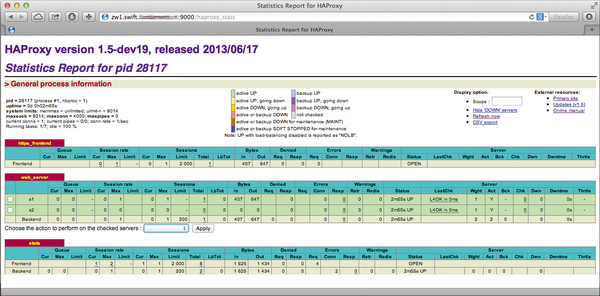 Abbildung 2: HAProxy ist eine Applikation, die ausschließlich im Userspace werkelt. Sie bietet eine übersichtliche Statistikseite, über die sich auch Backends aktivieren und deaktivieren lassen.
Abbildung 2: HAProxy ist eine Applikation, die ausschließlich im Userspace werkelt. Sie bietet eine übersichtliche Statistikseite, über die sich auch Backends aktivieren und deaktivieren lassen.
Hochverfügbarkeit für den Loadbalancer
Das vorgestellte HAProxy-Setup kommt mit einem kleinen Pferdefuß daher, um den sich der Admin noch zu kümmern hat: Zwar wäre der Zugriff auf die Webserver problemlos möglich, solange auch nur ein einziger Backend-Server im Rennen ist. Kritisch würde es allerdings, wenn der Rechner ausfällt, auf dem der Loadbalancer läuft: Dann würden Kunden, die sich mit der IP des Loadbalancers verbinden wollen, nämlich plötzlich im Regen stehen und merken, dass die gesamte Plattform nicht funktioniert. Es gilt insofern zu verhindern, dass der Loadbalancer zum hässlichen Single Point of Failure (SPOF) in der Installation wird. An dieser Stelle kommt wieder Pacemaker ins Spiel, der sich für diese Aufgabe ganz hervorragend eignet. Wer also ein Loadbalancer-Setup plant, der sollte sich mit Pacemaker zumindest grundlegend anfreunden – es sei denn, es käme eine kommerzielle Balancer-Lösung zum Einsatz, die sich des Themas HA automatisch annimmt.
Konkret bieten sich dem Admin zwei Möglichkeiten, das Problem in den Griff zu bekommen. Variante 1 sieht vor, die Loadbalancer-Software auf einen eigenen Failover-Cluster zu legen und Pacemaker die Aufgabe zu übertragen, stets für die HAProxy-Funktionalität zu sorgen. Mittels einer
»clone«
-Direktive wäre es sogar möglich, HAProxy-Instanzen auf beiden Servern laufen zu lassen und die Installation mit DNS-Round-Robin-Balancing zu kombinieren, so dass es nicht permanent einen funktionslosen Knoten in der Installation gibt.
Listing 2
enthält die beispielhafte Pacemaker-Konfiguration für eine solche Lösung mit dezidiertem Loadbalancer-Cluster. Der Vorteil: Die Last, die die Balancer selbst hervorrufen, bleibt separiert und beeinflusst nicht die Server, auf denen die Applikation läuft.
Listing 2
Pacemaker mit DNS-RR-HAProxy
Genau das wäre in Variante 2 der Fall: Hier ist die Annahme, dass einer der ohnehin vorhandenen Backend-Server einfach noch den Loadbalancer mit auf seine Kappe nimmt. Wiederum kombiniert mit Pacemaker wäre so sichergestellt, dass auf einem der Knoten stets ein Loadbalancer läuft, die Plattform also für eingehende Requests zur Verfügung steht. Falls die durch den Balancer verursachte Last vernachlässigbar klein ist, bietet sich eine solche Lösung insbesondere dann an, wenn insgesamt nur wenig Hardware verfügbar ist. Technisch sauber ist allerdings die Variante mit eigenem Balancer-Cluster.
Ähnliche Artikel
-
Workshop: Dienste ohne Pacemaker hochverfügbar betreiben

-
HAProxy als Webfrontend

-
HAProxy 1.8 ist da
Ab sofort steht die neueste stabile Version das HAProxy-Loadbalancers zur Verfügung.
-
HAProxy bekommt DNS Service Discovery
Im gegenwärtigen Trend zu dynamischer Infrastruktur will HAProxy nicht zurückbleiben und integriert immer mehr entsprechende Features.
-
OpenStack-Workshop, Teil 3: Gimmicks, Erweiterung und Hochverfügbarkeit

Konfigurationsmanagement

Themen


