
Data Placement in RADOS
Innerhalb eines RADOS-Clusters finden sich drei verschiedene Maps, nämlich einerseits die MON-Map, die eine Liste aller Monitoring-Server ist, die OSD-Map, in der sich alle physikalischen Object Storage Devices (OSDs) finden, und schließlich die Crushmap. Auf den OSDs selbst liegen die binären Objekte, also die tatsächlichen im Object-Store abgelegten Daten.
Nun kommen die Placement Groups (PG) ins Spiel: Nach außen hin wirkt es, als sei die Zuweisung von Storage-Objekten zu bestimmten OSDs rein zufällig. Tatsächlich erfolgt die Zuweisung hingegen anhand der Placement Groups. Jedes Objekt gehört zu einer solchen Gruppe. Vereinfacht dargestellt ist eine Placement Group eine Liste von verschiedenen Objekten, die im RADOS-Store abgelegt sind. Zu welcher Placement Group ein Objekt gehört, errechnet RADOS anhand des Namens des Objektes, des gewünschten Replikations-Levels sowie einer Bitmask, die die Summe aller PGs im RADOS-Cluster festlegt.
In der Crushmap, die der zweite Teil dieses Systems ist, steht die Information, welche Placement Groups wo im Cluster – also auf welchem OSD – landen sollen ( Abbildung 2 ). Replikation spielt sich stets auf der PG-Ebene ab: Alle Objekte einer Placement-Group werden im RADOS-Cluster zwischen verschiedenen OSDs repliziert.
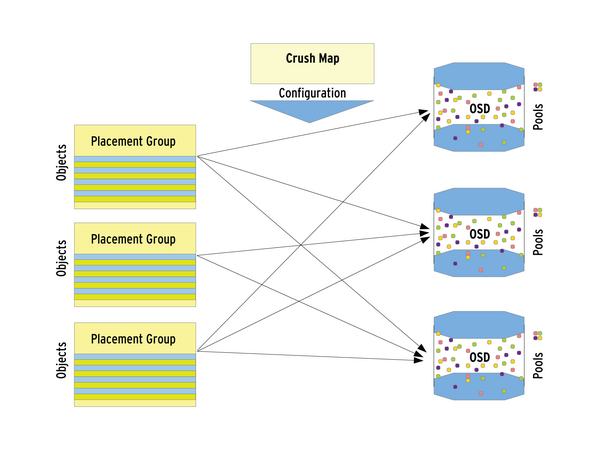 Abbildung 2: Die Elemente das RADOS-Universums, deren Zusammenspiel die Crush-Map steuert.
Abbildung 2: Die Elemente das RADOS-Universums, deren Zusammenspiel die Crush-Map steuert.
Die Crushmap verdankt ihrem Namen übrigens dem von ihr genutzten Algorithmus. Der Crush-Algorithmus wurde speziell im Hinblick auf einen Einsatzzweck wie bei RADOS entwickelt; er entstammt ebenfalls der Feder von Sage A. Weil. Sein Name ist ein Kunstwort, es steht für Controlled, Scalable, Decentralized Placement of Replicated Data. Sage Weil hebt ein Feature von Crush besonders hervor: Anders als Hash-Algorithmen verhält sich Crush auch dann stabil, wenn viele Storage-Devices gleichzeitig den Cluster verlassen oder hinzukommen. Das Rebalancing, das manch andere Storage-Lösung benötigt, sorgt meist für jede Menge Traffic und für entsprechend lange Wartezeiten. Crush-basierte Cluster verschieben hingegen gerade so viele Daten zwischen den Storage-Knoten, dass ein ausgeglichenes Verhältnis erreicht wird.
Das Data Placement manipulieren
Freilich hat im Hinblick auf die Frage, welche Daten wo landen, auch der Admin ein Wörtchen mitzureden. Praktisch alle Parameter, die die Replikation in RADOS betreffen, sind durch den Admin zu konfigurieren. Dazu gehört beispielsweise auch, wie oft ein einzelnes Objekt innerhalb des RADOS-Clusters existieren soll, wie viele Replicas es also davon gibt. Freilich steht es dem Admin ebenso frei, die Zuweisung der Replicas an OSDs zu manipulieren. So kann RADOS Rücksicht auf den Standort bestimmter Racks nehmen. Replikationsregelungen, die der Admin festlegt, steuern die Verteilung der Replicas von Placement Groups auf verschiedene OSD-Gruppen. Eine Gruppe kann dabei zum Beispiel alle Server in einem RZ-Raum enthalten und eine andere Gruppe die Server in einem zweiten Raum.
Wie die Replikation von Daten in RADOS funktioniert, legen Admins fest, indem sie die Crush-Regeln entsprechend manipulieren. Grundsätzlich gilt: Weder auf die Einteilung der Placement Groups noch auf die Ergebnisse der Crush-Kalkulationen lässt sich unmittelbar Einfluss nehmen. Stattdessen erfolgt die Festlegung der Replikationsregeln pro Pool; die Einteilung der Placement Groups und die Platzierung anhand der Crushmap erledigt RADOS im Anschluss allein. Ab Werk kommt RADOS mit einer Default-Regel, die besagt, dass pro Pool von jedem Objekt zwei Replicas zu existieren haben. Die Anzahl an Replicas ist stets pro Pool festzulegen; ein alltägliches Beispiel wäre es, diese Zahl auf 3 zu erhöhen. Das geht mit folgendem Befehl:
»ceph osd pool set data size 3«
Um die gleiche Änderung für den Pool
»test«
durchzusetzen, wäre an dieser Stelle
»data«
durch
»test«
zu ersetzen. Ob der Cluster im Anschluss tut, was der Admin von ihm erwartet, kann er mit
»ceph -v«
genauer untersuchen.
Diese Art der Bedienung unter Einsatz von
»ceph«
ist zweifellos angenehm, bietet aber nicht den vollen Funktionsumfang. Denn im Beispiel verwendet der Pool weiterhin die Crushmap, die ab Werk mitgeliefert wird. Sie lässt Eigenschaften wie das Rack, in dem ein Server hängt, außen vor. Wer Replicas anhand dieser Eigenschaften verteilen möchte, kommt nicht umhin, eine eigene Crushmap zu konstruieren.
Ähnliche Artikel





Konfigurationsmanagement

Themen


