Ein Blick in den Linux-Kernel mit Systemtap

Abgezapft

Früher hatte Linux nicht den besten Ruf, was seine Fähigkeiten für Tracing und Debugging betrifft. Das hat sich mit der Einführung des System Tracing and Profiling Framework (kurz Systemtap [1] ) geändert. In den letzten fünf Jahren ist Systemtap zu einem zuverlässigen Tool gereift und nun in den meisten Linux-Distributionen vorhanden. Es gibt auch ein Eclipse-basiertes Frontend für den Einsatz zur Systemanalyse oder zur Programmierung [2] .
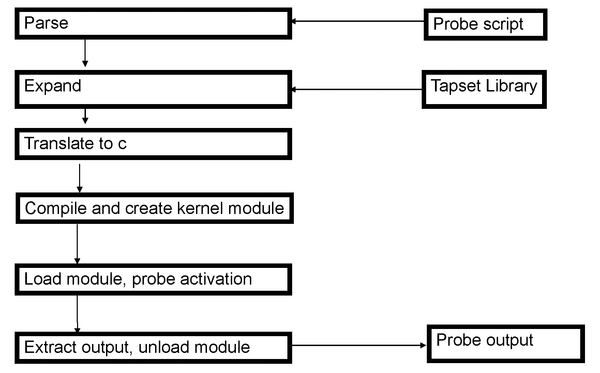 Abbildung 1: Der schematische Ablauf beim Einsatz von Systemtap.
Abbildung 1: Der schematische Ablauf beim Einsatz von Systemtap.
Administratoren und Entwickler könnten mit Systemtap in Echtzeit Informationen aus einem laufenden Linux-Kernel erhalten. Das Tool macht es einfach, Daten zu sammeln, die man später für Performance-Analyse oder Fehlersuche verwenden kann. Den Kernel mit speziellen Optionen zu übersetzen oder zu rebooten, ist mit Systemtap nicht nötig.
Systemtap bietet eine eigene Awk-ähnliche Programmiersprache
[3]
für eigene Skripte und lässt sich ansonsten über die Kommandozeile steuern. Die Informationen, die Systemtap ausgibt, ähneln der Ausgabe von Tools wie
»ps«
,
»top«
,
»sar«
,
»vmstat«
,
»iostat«
,
»free«
,
»uptime«
,
»mpstat«
,
»pmap«
,
»netstat«
,
»iptraf«
,
»tcpdump«
,
»strace«
,
»lsof«
oder dem Proc-Filesystem.
Die meisten dieser Tools beschränken sich auf einen Teilaspekt des Gesamtsystems und geben die gemessenen Werte immer im gleichen Format aus. Systemtap ist da flexibler, denn es kann eine breite Palette an Subsystemen gleichzeitig messen und so unter Umständen Beziehungen zueinander feststellen. Einen Messpunkt (Probe Point) im Kernel festzulegen, ist dabei sehr einfach.
Installation
Um mit Systemtap zu arbeiten, müssen alle nötigen Pakete installiert sein. Das bedeutet aber nicht nur, dass die Systemtap-Software installiert sein muss, sondern auch die Pakete mit den Debugging-Symbolen der untersuchten Programme, damit Systemtap zum Beispiel die Variablennamen an einem Probe Point anzeigen kann.
Die Beispiele in diesem Artikel wurden auf einem System mit Red Hat Enterprise Linux 5.5 ausgeführt, auf dem die folgenden Pakete installiert wurden:
- systemtap-runtime-1.1-3.el5.ix86.rpm
- kernel-debuginfo-2.6.18-194.el5.rpm
- kernel-debuginfo-common-2.6.18-194.el5.rpm
- kernel-devel-2.6.18-194.el5.rpm
Beispielsweise unter Ubuntu ist für die Debugging-Pakete ein eigenes Repository (
http://ddebs.ubuntu.com
) erforderlich, das Kernel-Entwickler-Paket heißt
»linux-headers«
.
Systemtap bringt schon eine Anzahl von Skripte mit, die zum Beispiel Informationen über den Kontext eines Messpunkts ausgeben oder eingebaute Events bereitstellen. Ein solches Skript wird in der Systemtap-Nomenklatur "Tapset" genannt. Mehr dazu verrät der gleichnamige Kasten.
Die Manpage zu
»stapfuncs«
führt Funktionen auf, die die Tapset-Bibliothek bereitstellt. Dies sind einige gebräuchliche Tapsets:
Tapsets
Bei Tapsets handelt es sich um Skripte, die Details über bestimmte Kernel-Subsysteme enthalten und sie anderen Skripten zur Verwendung anbieten. Tapsets können analog zu Bibliotheken bei C-Programmen verstanden werden. Sie verstecken die Implementierungsdetails eines Kernel-Subsystems und stellen dabei die nötigen Informationen für Messung und Überwachung zur Verfügung. Tapsets werden üblicherweise von Experten des jeweiligen Kernel-Bereichs geschrieben. Anwender, die mehr ins Detail gehen wollen, verwenden meistens keine fertigen Tapsets, sondern schreiben eigene Skripte für eine spezifische Anwendung.
-
»
tid()« : die aktuelle Thread-ID. -
»
pid()« : die Prozess-ID (Taskgroup-ID) des aktuellen Threads. -
»
execname()« : der Name des Prozesses. -
»
gettimeofday_ns()« : Nanosekunden seit der Epoche (1.1.1970).
Die Beispielskripte in diesem Artikel verwenden diese Tapsets, die Strings oder Zahlen zurückgeben, die sich mit der eingebauten Print-Funktion einfach ausgeben lassen. Alternativ gibt es die Funktion
»printf«
, die wie ihr C-Pendant Formatstrings verarbeitet, also etwa
»%s«
für einen String und
»%d«
für eine Integer-Zahl.
Die einfachste Probe ist eine, die nur ein Event verfolgt. Dies lässt sich bewerkstelligen, indem man an den richtigen Stellen Print-Statements in den Kernel einfügt. Diese Vorgehensweise ist oft der erste Schritt dabei, ein Kernel-Problem zu lösen: einen Aufruf näher zu untersuchen und zu sehen, was genau dabei passiert. Dabei wird Systemtap nur angewiesen, bei jedem Event eine Meldung auszugeben. Ein solches Skript besteht also nur aus dem Ort der Probe und der Ausgabe.
Zeitmessung
Als Nächstes könnte man messen, wie lange ein Aufruf dauert, beispielsweise der Systemcall
»open()«
. Die Zeitwerte sollen dabei in einem Array abgelegt werden, also muss Systemtap Werte aus einem Array lesen. Das funktioniert im Prinzip wie bei den meisten Programmiersprachen, also mit Indices und geschweiften Klammern, zum Beispiel:
delta = gettimeofday_ns() - zeit[tid()]
Setzen lassen sich Array-Werte analog:
zeit[tid()] = gettimeofday_ns()
Dieser Code setzt einen Zeitstempel, der als Referenz dient, um die Differenz zu berechnen. Wenn ein Skript die Zeile ausführt, setzt Systemtap den jeweiligen Wert für die Thread-ID als Index ein. Gleichzeitig liefert der Aufruf
»gettimeofday_ns()«
den gerade aktuellen Zeitstempel zurück. Am Ende bleibt ein Array mit den Thread-IDs als Schlüsseln und den Zeitstempeln als Werten.
Die erste Probe ist in
Listing 1
zu sehen. Sie misst die Zeit, die der Kernel im Systemcall
»open()«
verbracht hat, dessen Code in
»fs/open.c«
zu finden ist. Der Open-Aufruf besitzt die Syntax:
Listing 1
Open-Syscall
SYSCALL_DEFINE3(open, const char __user *,filename, int, flags, int, mode)
Die Anweisung
»syscall.
Funktion
«
platziert die Probe am Anfang der aufgeführten Funktion, sodass die Parameter als Kontextvariablen verfügbar sind.
»syscall.
Funktion
.return«
setzt die Probe dagegen direkt bei Rücksprung aus der Funktion, womit die Rückgabewerte in der Kontextvariable
»$return«
vorhanden sind. Die Funktion könnte auch die Parameter verändern, statt einen Wert zurückzugeben. Deshalb ist es ratsam, eventuell in der Return-Probe einen Blick darauf zu werfen.
Der folgende Aufruf startet die Probe mit dem Kommando
»stap«
und schreibt das Ergebnis des Testlaufs in die Datei
»output«
:
stap -o output probe1.stp
Listing 2 zeigt das Resultat von einem Probelauf, bei dem die Datei stevebest mit Gedit geöffnet wurde. Dabei dauerte der Open-Aufruf 9487ns.
Listing 2
Ergebnisse
syscall_open gedit -pid 3976 args ("/usr/share//mime/aliases", O_RDONLY|O_LARGEFILE)
sys_open spend 9503 ns to complete
syscall_open gedit -pid 3976 args ("/usr/share//mime/subclasses", O_RDONLY|O_LARGEFILE)
sys_open spend 8746 ns to complete
syscall_open gedit -pid 3976 args ("/home/best/.gnome2/gedit-metadata.xml", O_RDONLY)
sys_open spend 8487 ns to complete
syscall_open gedit -pid 3976 args ("/home/best/stevebest", O_RDONLY)
sys_open spend 9487 ns to complete
Listing 3
zeigt, wie einfach es ist, einen Zähler einzubauen, der die Anzahl der Aufrufe von
»open()«
zählt und sie am Ende ausgibt.
Listing 3
Anzahl Aufrufe
Das nächste Beispiel in
Listing 4
ist eine Probe für den Systemaufruf
»mkdir()«
, die das zu erzeugende Verzeichnis, den gewünschten Modus und das Ergebnis ausgibt. Diese Probe verwendet die Funktion
»user_string«
, um den Pfadnamen zu erfahren. Die Syntax für den Aufruf der Funktion ist:
Listing 4
mkdir()
user_string:string (addr:long)
Sie kopiert einen String aus dem Userspace an die gegebene Adresse. Der Quellcode für
»sys_mkdir()«
ist in der Datei
»fs/namei.c«
zu finden. Die Syntax für den Aufruf sieht so aus:
asmlinkage long sys_mkdir(const char * pathname, int mode)
Das Resultat beim Ausführen sieht dann in etwa so aus:
Creating directory steveb1 mode is 511 Created with rc 0
Das folgende Skript zeigt, wie man einem Problem auf den Grund geht, das seine Ursache in einer überaus großen Zahl von Schreibvorgängen zu haben scheint. Es verwendet das Tapset
»vfs«
der virtuellen Dateisystemschicht und ein assoziatives Array, um Buch über die Schreibvorgänge der einzelnen Prozesse zu führen.
Listing 5
zeigt das zugehörige Skript.
Listing 5
vfs_write()
Die VFS-Tapset-Library ist in der Datei
»vfs.stp«
implementiert, die sich in
»/usr/share/systemtap/tapset/«
befindet. Ein Blick in dieses Verzeichnis zeigt noch eine Reihe weiterer interessanter Tapset-Dateien, die man in eigenen Skripten verwenden kann. Die Kernelquellen für
»vfs_write()«
sind in
»fs/read_write.c«
zu finden. Wenn man das Skript aus
Listing 5
ausführt, ergibt sich eine Übersicht ähnlich zu der in
Listing 6
.
Listing 6
Ausgabe
*** write totals *** metacity (3582): 327 gnome-screensav (3716): 260 wnck-applet (3680): 222 gnome-panel (3586): 169 bonobo-activati (3592): 152 gnome-power-man (3647): 151 gnome-settings- (3562): 137 gnome-terminal (5745): 111 notification-da (3720): 102 simpress.bin (4020): 85
Weil nicht nur die Anzahl der Schreibvorgänge eine Rolle spielt, sondern auch die Frage, wie viele Bytes jeweils geschrieben (und gelesen) wurden, sollte man je nach Anwendungsfall auch dies genauer untersuchen. Dazu bieten sich die Syscalls
»sys_read()«
und
»sys_write()«
an, die in
»fs/read_write.c«
implementiert sind.
Listing 7
zeigt eine Probe, die die gelesenen und geschriebenen Datenmengen protokolliert.
Listing 7
sys_read() und sys_write()
Ähnliche Artikel
-
Anwendungen tracen mit Oprofile und Systemtap

-
Neues bei Fedora 13, Teil 2: Systemtap
-
Systemtap 3.0 veröffentlicht
Systemtap vereint klassische Tracing- und Profiling-Tools wie Strace und Oprofile und bietet dabei eine einfache und leistungsfähige Schnittstelle für den Benutzer.
-
Realistische Lasttests mit I/O Riot

Konfigurationsmanagement

Themen


