
Bindungen
Einige Dienste setzen gleich mehrere Ereignisse voraus. Das Lärmmessprogramm könnte beispielsweise seine Daten nicht nur auf der Festplatte speichern, sondern sie auch in regelmäßigen Intervallen an einen Server im Internet versenden. Das Messprogramm kann folglich erst dann starten, wenn zum einen das Dateisystem vorhanden und zum anderen das Netzwerk hochgefahren ist – also die Ereignisse
»filesystem«
und
»started network-manager«
eingetreten sind. Genau diese Bedingungen schreibt man jetzt einfach in die Job-Datei hinter
»start on«
und verknüpft sie mit einem
»and«
:
start on (filesystem and started network-manager)
Neben
»and«
gibt es noch das logische Oder (
»or«
). Zusammen mit den Klammern darf man mit ihnen nahezu beliebig komplexe Bandwurmbedingungen basteln, wie es unter anderem das Bootsplash-Utility Plymouth vormacht (zu den eckigen Klammern und
»runlevel«
später noch mehr):
start on (starting mountall or (runlevel[016] and (desktop-shutdown or stopped xdm or stopped uxlaunch)))
Man darf die Zeile zwar umbrechen und mit Tabulatoren etwas übersichtlicher formatieren, mehrere
»start on«
-Zeilen sind jedoch nicht erlaubt.
Auf welche Ereignisse die einzelnen Jobs warten beziehungsweise sie jeweils selbst absetzen, verrät der Befehl ( Abbildung 4 ):
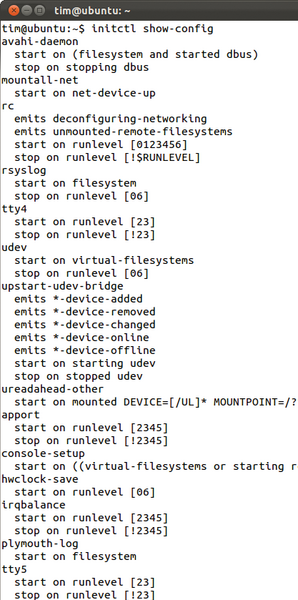 Abbildung 4: initctl show-config
Abbildung 4: initctl show-config
initctl show-config
Mit dem zusätzlichen Parameter
»-e«
dröselt er auch komplexe Bedingungen auf und zeigt an, welche Teile Ereignisse und welche andere Jobs sind (siehe auch
Kasten "Troubleshooting"
).
Ein Absturz des Lärmmessprogramms wäre ziemlich unangenehm. Selbst wenn ein Administrator sofort eingreifen würde, gingen für einige Zeit wertvolle Messwerte verloren. Glücklicherweise kann Upstart einen Dienst beobachten und bei einem Absturz automatisch neustarten. Dazu genügt es, in der Job-Datei eine Zeile mit dem Schlüsselwort
respawn
zu hinterlassen. Damit Upstart den Dienst im Auge behalten kann, startet es übrigens standardmäßig alle Prozesse im Vordergrund. Man kann das nur umgehen, indem sich der hinter
»exec«
eingetragene Dienst selbst forkt.
Der automatische Neustart hat allerdings auch einen kleinen Haken: Würde der Dienst durch einen Programmfehler immer wieder das Zeitliche segnen, würde ihn Upstart in einer Endlosschleife immer wieder reanimieren – und damit unter Umständen sogar das ganze System überlasten. Um das zu verhindern, ist es möglich, in der Job-Datei eine Zeitspanne vorzugeben. Mit dem Zweizeiler:
respawn 5 60 respawn
fährt Upstart das Messprogramm lediglich fünf Mal in 60 Sekunden neu hoch. Das erste
»respawn«
stellt dabei nur die Zeitspanne ein, das zweite aktiviert schließlich die automatische Wiederbelebung.
Reinigungspersonal
Häufig muss man vor dem Start eines Dienstes noch ein paar Dinge geraderücken beziehungsweise nach seinem Ableben etwas aufräumen. Das Lärmmessprogramm will seine Daten im Verzeichnis
»/var/log/laerm«
ablegen. Es wäre also eine gute Idee, es vor seinem Start einzurichten. Glücklicherweise darf man in der Job-Datei ein Shellskript hinterlegen, das Upstart noch vor dem eigentlichen Start des Dienstes ausführt:
pre-start script # Erstelle alle notwendigen Verzeichnisse mkdir -p /var/log/laerm end script
Das Skript steht dabei zwischen
»pre-start script«
und
»end script«
. Es ist ausschließlich für vorbereitende Maßnahmen gedacht und darf nicht den eigentlichen Dienst starten. Im obigen Beispiel stellt es sicher, dass die Messsoftware das Verzeichnis für Ihre Daten findet. Analog gibt es eine
»post-stop script«
-Sektion, die Upstart immer dann abarbeitet, wenn der Dienst terminiert. Für gewöhnlich räumen die dortigen Shell-Befehle auf, beim Messprogramm etwa:
post-stop script # Räume auf: rm -rf /var/log/laerm end script
Abschließend gibt es noch ein
»post-start«
-Skript, das Upstart immer zeitgleich mit dem hinter
»exec«
angegebenen Dienst startet.
Die oben aufgeführten
»pre-start«
und
»post-stop«
-Skripte bestehen eigentlich nur aus einer Zeile, weshalb man sie auch etwas kürzer als
pre-start exec mkdir -p /var/log/laerm
und
post-stop exec rm -rf /var/log/laerm
schreiben darf.
Ähnliche Artikel
-
ADMIN-Tipp: Autologin auf der Console
Vor allem in Testumgebungen ist es mühsam, sich immer wieder aufs Neue einloggen zu müssen. Ein automatisches Login lässt sich außer auf dem grafischen Desktop auch auf der Linux-Console realisieren.
-
Wiki hilft Ubuntu-Nutzern beim Systemd-Umstieg
In der kommenden Ubuntu-Version löst Systemd das Init-System Upstart ab. Ein Eintrag im Ubuntu-Wiki hilft beim Umstieg.
-
Upstart 1.6 merkt sich Prozesse
Ubuntus Init-System Upstart ist in Version 1.6 veröffentlicht worden.
-
Workshop: Open Source-Tipp

-
Billig-VPN mit AutoSSH
Wer vorübergehend eine stabile verschlüsselte Verbindung braucht, sollte einen Blick auf AutoSSH werfen.
Konfigurationsmanagement

Themen


