ADMIN-Tipp: UTF-8 im E-Mail-Subject
Wir schreiben das Jahr 2013. Ganz Linux ist auf UTF-8 umgestellt. Ganz Linux? Nein. Einige Programme aus den Anfangszeiten des Internet haben immer noch ihre Schwierigkeiten mit allem, was sich außerhalb der ASCII-Welt bewegt. Dazu gehört insbesondere E-Mail, für die es einige Umwege gibt, um dennoch andere Zeichencodierungen wie UTF-8 zum Adressaten zu befördern.
Für den Mail-Body gibt es mittlerweile schon 8-Bit-Extensions, mit denen sich UTF-8-Mails direkt verschicken lassen (etwa "Content-Type: text/plain; charset=UTF-8"), aber beim Header geht das nicht, denn er darf nur ASCII-Zeichen enthalten. Deshalb gibt es dafür Verfahren, die UTF-8-Zeichen über MIME kodieren (siehe RFC 2047). Prinzipiell gibt es dafür zwei Wege: Quoted Printable und Base64. Der grundsätzliche Aufbau eines so codierten Subjects sieht so aus:
=?charset?encoding?text?=
Das Character Set ist dann "UTF-8", für das Encoding gibt es die beiden Abkürzungen B (Base64) und Q (Quoted Printable) (siehe RFC 1342). Die meisten Mail-Clients verarbeiten solche Kodierungen automatisch, sodass man meistens nur das Ergebnis zu sehen bekommt. Wer aber etwa mit Procmail das Mail-Subject verarbeiten will, muss dazu erst einmal den Inhalt dechiffrieren. Der Trick besteht dann darin, in einer Regel erst das MIME-Encoding zu matchen und das Subject entsprechend zu decodieren. Dann kann eine zweite Regel das Subject überprüfen.
Für Base64 sieht der erste Teil einer Procmail-Regel so aus:
* ^Subject:.*=\?utf-8\?B\?\/.+\?=
Den Match der Regular Expression dekodiert man mit dem "base64"-Kommando und schreibt sie in eine Variable, die eine zweite Procmail-Regel dann auf das Suchmuster hin prüft:
DECODEDSUBJECT=`echo $MATCH | sed s/?=// | base64 -d` * DECODEDSUBJECT ?? Suchmuster
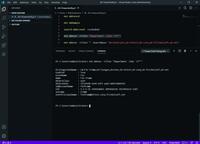
Im Body der inneren Regel lässt sich die Mail wie gewohnt mit Procmail verarbeiten. Die komplette Konfiguration sieht dann so aus:
:0
* ^Subject:.*=\?utf-8\?B\?\/.+\?=
{
DECODEDSUBJECT=`echo $MATCH | sed s/?=// | base64 -d`
:0
* DECODEDSUBJECT ?? Suchmuster
{
:0c
Mail/specialfolder
}
}
Ähnliche Artikel
-
Yahoo will Ende-zu-Ende-Verschlüsselung einführen
Bis 2015 möchte Yahoo die Verschlüsselung von Nachrichten per PGP anbieten.
-
Workshop: Spamschutz mit SpamAssassin

-
Windows Active Directory mit der PowerShell verwalten
-
Workshop: Outlook-Mails mit regulären Ausdrücken durchsuchen

-
Workshop: Spam- und Viren-Schutz mit Proxmox

Konfigurationsmanagement

Themen


