
SMART-Tests in zwei Varianten durchführen
Der SMART-Standard sieht auch eigene Tests vor. Die Tests können in zwei verschiedenen Prioritäten gestartet werden, wobei “background” sehr praxisgerecht im Hintergrund läuft, und zwar nur, wenn sich die Platte im Leerlauf (idle) befindet. Die Tests können somit problemlos im laufenden Betrieb angeworfen werden und haben lediglich eine etwas längere Laufzeit als “foreground”-Tests, bei denen jede weitere Anfrage mit “CHECK CONDITION” beantwortet wird (was im Betriebssystem zu Timeout-Fehlern führt).
Zwei (eigentlich drei) Tests stehen zur Verfügung: Short, Long und Conveyance. Der letzte Test ist nur für (S)ATA-Platten verfügbar und soll Schäden beim Transport erkennen können. Interessant ist jedoch der “Short-Test”, der in der Regel nur zwei Minuten läuft und ein defektes Laufwerk schnell identifizieren kann. Der Test besteht aus drei Schritten, wobei hier jeder Hersteller eigene Testroutinen implementiert hat: Zunächst werden die elektrischen Eigenschaften überprüft, also Controller-Chip, RAM, Schreib-/Lese-Schaltungen und die übrige Elektronik. Die mechanischen Eigenschaften (Motor, Servos, Positionierungsmechanik) werden im zweiten Schritt getestet. Schließlich wird zuletzt noch ein bestimmter (recht kleiner) Teilbereich der Platte gelesen und überprüft.
Der “Long-Test” wurde eigentlich für die Qualitätskontrolle beim Hersteller entwickelt und besteht aus dem Short-Test, der allerdings auch länger und
intensiver ausfallen kann, und dem zusätzlichen Prüflesen der gesamten Plattenoberfläche. In der Praxis lässt sich der Short-Test regelmäßig zum schnellen Prüfen anwerfen,
smartctl -t short /dev/sda
der Long-Test hingegen könnte einmal am Wochenende gestartet werden:
smartctl -t long /dev/sda
Das Ergebnis der Tests speichert SMART in einer Tabelle und zeigt sie per
smartctl -l selftest /dev/sda
an. Bei laufenden Tests zeigt -a statt -l die verbleibende Restzeit, beispielsweise “72% of test remaining”, und die gesamte Laufzeit des Tests unter “Long (extended) Self Test duration: 1624 seconds [27,1 minutes]” an (Bild 2). Jeder Test kann problemlos unterbrochen werden, ob durch das Ausschalten des Rechners oder über
»smartctl -X /dev/sda«
. Die Manages zeigen weitere Parameter, unter anderem auch zum Test nur bestimmter Bereiche (
»-t select200-600«
). Sollten Probleme beim Start der Tests auftreten, könnte es sein, dass der Hersteller die SMART-Voreinstellungen recht ungewöhnlich oder falsch gesetzt hat. Beim Systemstart kann Smartctl ein solches Laufwerk per
smartctl —smart=on —offlineauto=on —saveauto=on /dev/sda
korrekt einstellen.
|
Relevante SMART-Werte |
|
|
Wert |
Bedeutung |
|
Spin_Up_Time (ID:3) |
Die Zeit in Millisekunden, die der Plattenstapel beim Hochfahren benötigt, um auf Nenndrehzahl zu kommen. Steigt dieser Wert plötzlich an, deutet das auf ein defektes Plattenlager oder Motorprobleme hin. |
|
Spin_Retry_Count (ID:10) |
Anzahl der Fehlstarts beim Hochdrehen des Plattenstapels. Dreht der Plattenstapel nach kurzer Zeit nicht mit Nenndrehzahl, wird ein erneuter Startversuch unternommen. Beginnt dieser Wert über 0 zu steigen, deutet das auf ein defektes Plattenlager oder Motorprobleme hin. |
|
Calibration_Retry_Count (ID:11) |
Anzahl der Rekalibrierungsversuche. Schaffen es die Köpfe nicht, sich in der vorgegebenen (kurzen) Zeit genau über einer Spur zu platzieren, muss eine Rekalibrierung initiiert werden. Steigt dieser Wert, deutet das vor allem bei älteren Laufwerken auf beginnende Probleme der Festplattenmechanik hin. |
|
Power_On_Hours (ID:9) |
Anzahl der Betriebsstunden. Der Wert wächst im Laufe der Zeit und zeigt lediglich das Alter der Festplatte in Stunden (manchmal Minuten oder Sekunden) an. |
|
Temperature_Celsius (ID:194) |
Aktuelle Temperatur im Laufwerk. Der Wert sollte ganz grob möglichst im Bereich von 30 bis 40°C liegen — zu warme Festplatten (>45°C), aber auch kalte Platten ( |
|
UDMA_CRC_Error_Count (ID:199) |
Anzahl der fehlerhaften Übertragungen zwischen Festplatte und Controller. Werte über 0 deuten auf schlecht eingesteckte Verbindungskabel, mangelnde Abschirmung oder Wackelkontakte hin. Sehr hohe Werte (mehrere tausend) können ihre Ursache in einem defekten Controller-Chip haben. |
|
Reallocated_Sector_Ct (ID: 5) |
Anzahl der reallozierten Sektoren. Sobald ein Sektor mehrfach nicht mehr korrekt gelesen/geschrieben/geprüft werden kann, wird er in einen reservierten Bereich der Platte ausgelagert (sparse area). Dies ist ein deutliches Warnzeichen, weil es auf beginnende Oberflächenprobleme hinweist. Beginnt dieser Wert über 0 zu wachsen, steht oft ein Festplattenausfall (head-crash) bevor. |
|
Seek_Error_Rate (ID:7) |
Eine nicht näher spezifizierte Rate für Positionierungsfehler der Schreib-/Leseköpfe. Steigt dieser Wert, deutet das auf Probleme mit der Positionierung der Köpfe hin - Ursache können Servofehler, thermische Ausdehnung oder mechanische Ausfallerscheinungen sein. |
|
(Raw_)Read_Error_Rate (ID:1) |
Eine nicht näher spezifizierte Rate für Lesefehler. Ein steigender Wert bedeutet, dass die Oberfläche der Platten beschädigt ist oder die Schreib-/Leseköpfe fehlerhaft arbeiten. |
|
Uncorrectable_Sector_Count (ID:198) |
Anzahl der Versuche, fehlerhafte Sektoren ohne Erfolg zu lesen oder zu schreiben. Ein steigender Wert zeigt defekte Plattenoberflächen oder Fehler in den Schreib-/Leseköpfen an. |
|
Free_Fall_Protection (ID:254) und G-Sense_Error_Rate (ID:221) |
Wird bei Notebook-Festplatten die “Free Fall Protection” ausgelöst (Platte befindet sich bei 0 G im freien Fall) und/oder gibt es Fehler durch zu hohe G-Raten (Vibrationen, Stöße), steigen diese Werte. Das wiederum deutet auf einen sehr rauhen Umgang mit dem Notebook hin. |
|
Load_Cycle_Count (ID:193) |
Anzahl der Unload/Load-Zyklen der Schreib-/Leseköpfe. Viele (Notebook-)Festplatten parken ihre Köpfe (unload) nach wenigen Sekunden Leerlauf, um Energie zu sparen. Schreibt ein Betriebssystem wie Linux alle paar Sekunden beispielsweise in eine Log-Datei, müssen die Köpfe dazu wieder “ent-parkt” werden (load). Die maximale Anzahl von Unload-/Load-Zyklen sollte je nach Hersteller 100.000 bis 600.000 nicht überschreiten, wächst im obigen Szenario jedoch um über 100 pro Stunde. Das Unload-/Load-Maximum ist so innerhalb eines Jahres erreicht. Abhilfe schafft ein Abschalten der Energiespar-Option. |
|
Current_Pending_Sector_Ct (ID:197) |
Dieser besondere Wert zeigt die aktuell nicht korrekt les- oder schreibbaren Sektoren an, die noch nicht remapped wurden. Ist ein Sektor auch nicht mit Hilfe der Fehlerkorrektur (ECC) lesbar, erhält er zunächst den Status “current pending sector”. Der Sektor wird nun aber noch nicht remapped, weil sein Inhalt (bei Lesefehlern) ja nicht bekannt ist und ein späterer Versuch vielleicht erfolgreich ist. Erst nach mehreren erfolglosen Lese-Versuchen wird der Sektor als fehlerhaft markiert und Reallocated_Sector_Ct (ID: 5) um den Wert 1 erhöht. Wird andererseits schreibend auf den Sektor zugegriffen, müssen die Daten zuvor logischerweise nicht gelesen werden. Die Festplatte markiert den Sektor dann endgültig als fehlerhaft und mapped ihn in den reservierten Bereich um. |
Reparaturarbeiten
Wirklich spannend wird es, wenn SMART bei einem Test Sektoren nicht mehr lesen kann, diese aber noch nicht remapped wurden. Konkret ist dann der Wert Current_Pending_Sector_Ct (ID:197) größer als Null. Es muss noch keine SMART-Warnung geben, und selbst wen, kommt sie eigentlich zu spät – befindet sich ein defekter Sektor innerhalb einer Datei, kann diese nun auch durch ein Backup nicht mehr gerettet werden. Schlimmer ist, dass man nicht einmal weiß, um welche Datei es sich handelt - oder ob der Sektor im ungenutzten Bereich der Festplatte liegt und so zunächst keinen Schaden anrichtet. Gibt
smartctl -l selftest /dev/sdb
als Status “Completed: read failure” und einen Wert ungleich Null für “LBA_of_first_error” aus (zum Beispiel “0x 0654321”), befindet sich zumindest ein defekter Sektor an der angegebenen Position, oft folgen weitere. Der Befehl
smartctl -A /dev/sdb
gibt nur die Tabelle der Attribute aus (im Gegensatz zu “-a”, das alle Infos ausgibt). Der Wert Current_Pending_Sector_Ct (ID:197) zeigt konkret die Anzahl der problematischen Sektoren an, beispielsweise “1”. Mit
»fdisk«
lässt sich herausfinden, auf welcher Partition der problematische Sektor liegt:
fdisk -lu /dev/sdb
Es ist die Partition, innerhalb deren Grenzen der von LBA_of_first_error gemeldete Sektor liegt. Nun muss der Offset des Sektors berechnet werden, also seine relative Position innerhalb der Partition. Dazu zieht man die Nummer des Start-Sektors von der fehlerhaften Sektornummer ab. Der gesuchte Sektor liegt beispielsweise an Position 654321-63=654258 innerhalb der Partition
»/dev/sdb1«
. Welches Dateisystem die Partition verwendet und wo es eingehängt wurde, verrät
»/etc/fstab«
oder
»mount.«
Nun muss noch die Blockgröße des Dateisystems bestimmt werden (Listing tune2fs verrät die Blockgröße):
tune2fs -l /dev/sdb1 | grep Block
Listing: tune2fs verrät die Blockgröße
[root@delius ~]# tune2fs -l /dev/sdb1 | grep Block Block count: 122096000 Block size: 4096 Blocks per group: 32768
Die “block size” beträgt in der Regel 4096 Byte. Nun kann man berechnen, in welchem Block des Dateisystems sich der Sektor befindet. Dazu wird die relative Position des Sektors (654258) mit der Sektorgröße (512 Byte) multipliziert und dieser Wert durch die Blockgröße (4096) geteilt. Im Beispiel kommt dabei
(654321-63)*512/4096 = 81782,25
heraus. Die Blockgröße beträgt 4096 Byte, ein Block (Cluster) besteht also aus 8 Festplatten-Sektoren zu je 512 Byte. Die 0,25 kennzeichnen demnach den zweiten Sektor (0,125 je Sektor) im Block/Cluster als problematisch. Mit diesen Informationen kann nun der Dateisystem-Debugger debugfs gefüttert werden, der mit Ext2/Ext3/Ext4 arbeitet. In dessen Shell öffnet open /dev/sdb1 die entsprechende Partition in wenigen Sekunden im Dateisystem-Debugger. Zu welcher Datei ein bestimmter relativer Sektor gehört, stellt
testb 81782
fest. Mit Glück erhalten Sie die Ausgabe “Block 81782 not in use”. Der kippende Sektor befindet sich also im ungenutzten Bereich des Dateisystems, Sie können ein Backup anlegen und das Laufwerk austauschen. Bei einem “Block 81782 marked in use” überspannt eine Datei den Sektor. Den entsprechenden Inode gibt
icheck 81782
nach einer nervenaufreibend langen Wartezeit aus (hier 21200970), Pfad und Dateinamen erhalten Sie schließlich per
»ncheck 21200970«
(Listing “Mit debugfs auf der Suche nach kaputten Dateien”).
Listing: Mit debugfs auf der Suche nach kaputten Dateien
[root@delius ~]# debugfs debugfs 1.41.12 (17-May-2010) debugfs: open /dev/sdb1 debugfs: testb 81782 Block 81782 marked in use debugfs: icheck 81782 Block Inode number 81782 21200970 debugfs: ncheck 21200970 Inode Pathname 21200970 /Vms/ISOs/Ubuntu/ubuntu-6.06.2-server-i386.iso
Die weitere Vorgehensweise kann nun recht unterschiedlich sein. Ist die Datei unwichtig oder leicht ersetzbar, wie etwa eine Manpage oder ein freies ISO-Image, ist man nochmal mit einem blauen Auge davongekommen. Bei wichtigen Dateien können mehrere Leseversuche per cp eventuell zum Erfolg führen, sofern die Fehlerkorrektur (ECC) die kaputten Bits ersetzen kann. Problematisch wird es, wenn die Datei noch benötigt wird und es keine Kopie und kein Backup gibt.
Das BadBlock-Howto der Smartmontools [3] beschreibt, wie man SMART dazu bringt, den kippenden Sektor durch Überschreiben umzumappen. Der von Current_Pending_Sector_Ct (ID:197) gemeldete Sektor wird beispielsweise per
dd if=/dev/zero of=/dev/sdb bs=512 count=1 seek=654321
sync
mit Nullen überschrieben. Ein erneuter Aufruf von
smartctl -A /dev/sdb
sollte nun einen Current_Pending_Sector_Ct (ID:197) weniger und einen Reallocated_Sector_Ct (ID: 5) mehr anzeigen. In der Praxis bringt das allerdings recht wenig, da die meisten Dateien, in deren Mitte sich irgendwo 512 Nullen befinden, unbrauchbar sind. Bei ASCII-Texten kann man den Inhalt vielleicht noch restaurieren, bei Filmen kann man mit einem kurzen Aussetzer leben. Office-Dokumente, Bilder und vor allem natürlich Programme oder Datenbanken sind allerdings meistens unbrauchbar. Statt dann unterhalb des Dateisystems mit
»dd«
herumzuexperimentieren, kann man die sowieso verlorene Datei auch gleich mit einer mindestens gleichgroßen Datei überschreiben – der Effekt ist derselbe.
Bei wirklich lebenswichtigen Dateien sollte das Laufwerk ohnehin ausgebaut und an ein professionelles Datenrettungslabor eingeschickt werden. Die Kosten für die Restauration sind allerdings recht hoch – aber immer noch billiger, als beispielsweise seine Kundendatenbank zu verlieren.
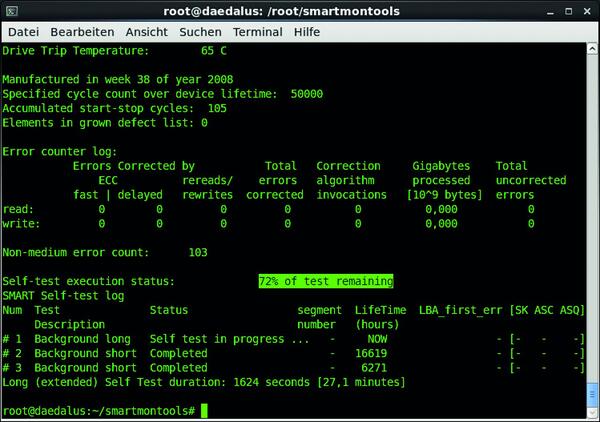 Bild 2: Der ausführliche SMART-Oberflächentest (long) stört den laufenden Betrieb nicht, läuft aber durchaus mehrere Stunden
Bild 2: Der ausführliche SMART-Oberflächentest (long) stört den laufenden Betrieb nicht, läuft aber durchaus mehrere Stunden
Ähnliche Artikel




Konfigurationsmanagement

Themen


