
Marschroute
Zu Anfang soll das bekannte Beispiel der Warteschlange vor der Kasse im Supermarkt grundlegende Queueing-Konzepte erklären ( Abbildung 3 ). Danach wird dieses fundamentale Konzept so erweitert, dass sich damit die Skalierbarkeit einer dreischichtigen E-Commerce-Anwendung vorhersagen lässt ( Listing 1 ). Gegen Ende des Artikels rücken schließlich realitätsnahe Erweiterungen der vorgestellten Leistungsmodelle und praktische Ratschläge für ihren Aufbau ins Blickfeld. Alle Beispiele verwenden Perl und das Open-Source-Queueing-Analysetool Pretty Damn Quick (PDQ), das der Autor zusammen mit Peter Harding pflegt. Es findet sich hier [6] .
Listing 1
E-Commerce-Modell
 Abbildung 3: Kunden stehen in einem Lebensmittelmarkt Schlange.
Abbildung 3: Kunden stehen in einem Lebensmittelmarkt Schlange.
Warum Warteschlangen?
Buffer und Stacks sind in Computersystemen allgegenwärtig. Beim Buffer handelt es sich um eine Warteschlange, bei der die Reihenfolge des Eintreffens von Anforderungen die Reihenfolge ihrer Abarbeitung diktiert. Man spricht hier auch von FIFO (first-in, first-out) oder FCFS (first come, first served). Im Gegenzug dazu bedient ein Stack Anforderungen in LIFO-Reihenfolge (last-in, first-out); es handelt sich um eine LCFS-Warteschlange (last-come, first served). Unter Linux ist etwa der History-Buffer der Shell eine bekannte Warteschlange. Wie jede physikalische Implementierung ist er durch die endliche Menge an Speicherplatz (die Kapazität) beschränkt. In der Theorie kann eine Warteschlange jedoch eine unbegrenzte Kapazität besitzen, so wie das auch bei PDQ der Fall ist.
Eine Warteschlange ist eine gute Abstraktion für gemeinsam genutzte Ressourcen. Ein sehr bekanntes Beispiel ist die Kasse im Supermarkt. Diese Ressource besteht aus Aufträgen (den Menschen, die Schlange stehen) sowie einer Bedienstation (der Kassiererin). Wenn man mit dem Einkaufen fertig ist, will man so schnell wie möglich den Laden verlassen, das ist das Performanceziel. Man kann dieses Ziel auch so formulieren, dass es darauf ankommt, möglichst wenig Zeit in der Schlange zu verbringen – man spricht hier von der Verweilzeit (R).
Nachdem sich ein Kunde für eine bestimmte Kasse entschieden hat und sich anstellt, besteht seine Verweilzeit aus zwei Komponenten: zum einen aus der Zeit, die er in der Warteschlange verbringt bevor er zur Kasse gelangt, und zum anderen aus der Zeit für die Bedienung durch die Kassiererin, in der sie die Einkäufe über den Scanner zieht, das Geld annimmt und herausgibt. Geht man nun davon aus, dass jede Person in der Warteschlange mehr oder weniger die gleiche Menge Artikel im Einkaufswagen hat, dann kann man erwarten, dass sich die Bedienzeiten pro Kunde im Schnitt angleichen. Darüber hinaus steht die Länge der Warteschlange offensichtlich im direkten Bezug zur Anzahl der Kunden im Laden. Wenn der Supermarkt fast leer ist, wird die durchschnittliche Wartezeit um einiges kürzer sein als zu Stoßzeiten.
Die Abstraktion der Warteschlange ( Abbildung 4 ) bietet ein leistungsfähiges Paradigma, mit dessen Hilfe sich (unter anderem) die Leistung von Computersystemen und Netzwerken ermitteln lässt. Ihr besonderer Vorzug ist, dass sie die ansonsten unterschiedlichen Leistungsdaten, die die Monitoring-Tools liefern, in einem Modell zusammenfasst.
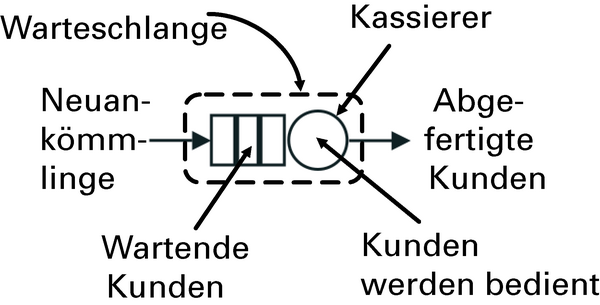 Abbildung 4: Komponenten einer symbolischen Warteschlange.
Abbildung 4: Komponenten einer symbolischen Warteschlange.
Dieser Artikel nimmt immer wieder Bezug auf die Metriken in Tabelle 1 und zwar insbesondere auf die Beziehung zwischen der Verweilzeit (R), der Servicezeit (S) und der Ankunftrate (t):
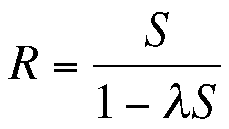 (1)
(1)
Tabelle 1
Interessante Leistungsmetriken
|
Symbol |
Metrik |
PDQ |
|---|---|---|
|
l |
Ankunftrate |
Input |
|
S |
Bedienzeit |
Input |
|
N |
User-Last |
Input |
|
Z |
Denkzeit |
Input |
|
R |
Verweilzeit |
Output |
|
R |
Antwortzeit |
Output |
|
X |
Durchsatz |
Output |
|
p |
Auslastung |
Output |
|
Q |
Warteschlangenlänge |
Output |
|
N* |
Optimale Last |
Output |
Man kann Gleichung (1) als sehr einfaches Performancemodell betrachten. Die Eingaben für das Modell stehen auf der rechten Seite, die Ausgaben auf der linken. Nach genau demselben Schema funktionieren auch die Berechnungen mit PDQ. Durch dieses einfache Modell sieht man sofort, dass bei geringem Publikumsverkehr, die zum Passieren der Kasse benötigte Zeit (die Verweilzeit) ausschließlich aus der eigenen Servicezeit besteht. Wenn keine weiteren Personen eintreffen ( =0), dann fällt nur die Zeit an, die man selbst benötigt, um die Waren eingeben zu lassen und zu bezahlen.
Wenn das Geschäft jedoch stark frequentiert ist, sodass für das Produkt λS → 1 gilt, dann steigt auch die Verweilzeit sehr stark an. Das rührt daher, dass sich die Länge der Warteschlange aus der Gleichung
 (2)
(2)
berechnet. Mit anderen Worten: Die Verweilzeit steht im direkten Bezug zur Warteschlangenlänge mal Eintreffrate und umgekehrt.
Gleichung (2) stellt außerdem den Bezug zu den Überwachungsdaten her. Die Daten für die durchschnittliche Auslastung in Abbildung 2 sind Echtzeitwerte, gemessen über relativ kurze Zeitabschnitte, beispielsweise eine Minute. Für die Berechnung der Warteschlangenlänge (Q) wird dagegen der Durchschnittswert über die gesamte Messdauer von 24 Stunden verwendet. Will man sich das bildlich vergegenwärtigen, so kann man sich Q als Höhe eines imaginären Rechtecks vorstellen, das die gleiche Fläche hat wie die Kurve der Überwachungsdaten über demselben 24-Stunden-Zeitabschnitt. Eine dazu analoge Beziehung gilt, wenn man die Wartezeit aus der Verweilzeit (R) in (2) ausklammert:
 (2)
(2)
Mit anderen Worten: Ersetzt man auf der rechten Seite der Gleichung die Verweilzeit R durch die Servicezeit S, dann entspricht auf der linken Seite die Ausgabemenge der Auslastung in Tabelle 1 .
Ähnliche Artikel





Konfigurationsmanagement

Themen


