
Ein zweites MySQL
Analog zur Konfiguration des ersten My-SQLs braucht es eine komplette zweite MySQL-Datenbank – auch in Pacemaker. Eine etwaige DRBD-Ressource kann
»mysql2«
heißen und der dazugehörige Mountpoint
»/mnt/mysql2«
. Die Pacemaker-Ressourcen inklusive Master-Slave-Setup vom schon vorhandenen MySQL lassen sich analog übernehmen, lediglich die verwendeten Namen und Parameter sind anzupassen. Indem eine zweite Service-IP definiert wird, zum Beispiel 192.168.0.4, erhält die Test-Datenbank eine Adresse. Auch die IP- sowie die Filesystem-Ressource sind analog zu übernehmen. Statt
»g_mysql«
heißt die zweite Gruppe
»g_mysql2«
. Die Parameter der zweiten MySQL-Ressource namens
»res_mysql2«
sind freilich ebenfalls anzupassen, hier könnte das PID-File
»/var/run/mysqld/mysqld2.pid«
und das Socket-File
»/var/run/mysqld/mysqld2.sock«
heißen. Datadir wäre freilich
»/mnt/mysql2«
. Mittels Colocation und Order wird die zweite DRBD-Ressource mit
»g_mysql2«
verknüpft.
Versicherung gegen Umsturz
Wenn auch die zweite MySQL-Datenbank läuft und vollständig in Pacemaker integriert ist, fehlt bloß noch ein Colocation-Constraint mit Punktwert
»-inf:«
, um die beiden Datenbanken voneinander zu trennen. Im Beispiel sähe dieser so aus:
colocation co_mysql2_never_follows_mysql-inf: ms_drbd_mysql2:Master ms_drbd_mysql:Master
Praktisch verhindert dieser Colocation-Constraint, dass die DRBD-Ressource
»mysql2«
dort Primary wird, wo die Ressource
»mysql«
bereits Primary ist. Fällt ein Clusterknoten aus, bleibt nur die Datenbank
»mysql«
übrig. Die komplette Konfiguration für ein solches Setup mit Befehlen der CRM-Shell findet sich im Kasten Aktiv-Aktiv-Setup.
DRBD und Pacemaker kommen jeweils mit Werkzeugen daher, die jede Menge verschiedene Parameter verstehen. Eine übersichtliche Referenz auf zwei Din-A4-Seiten, verfasst vom Autor dieses Artikels, finden Sie auf der Homepage von LINBIT unter [4] und [5] .
Hochverfügbares MySQL
Die im Artikel beschriebene Vorgehensweise, um eine MySQL-Datenbank hochverfügbar zu machen, geht vom Standard-Beispiel aus: Ein simpler Fail-Over-Cluster, in dem MySQL die Hauptanwendung ist. In der Praxis funktioniert dieses Prinzip zwar sehr verlässlich, bringt allerdings auch ein großes Problem mit sich. Der Grund hierfür liegt tief in den Strukturen der InnoDB-Engine, die MySQL standardmäßig verwendet und welche die mit Abstand meistgenutzte Engine überhaupt ist. Im Anschluss an einen Crash prüft MySQL die vorhandenen Datenbanken auf ihre Konsistenz und nimmt falls nötig entsprechende Korrekturen vor. Je größer die vorhandene Datenmenge ist, desto länger dauert dieser Vorgang. Dem Cluster-Manager vermeldet der Resource-Agent für MySQL zwar kurz nach dem Aufruf mit
»start«
den erfolgreichen Start, bis die Datenbank aber tatsächlich wieder auf Anfragen antwortet, dauert es bisweiligen einige Minuten. Obwohl der Clusterstack selbst also in kurzer Zeit einen brauchbaren Zustand wiederherstellt, dauert es sehr viel länger, bis die durch einen Fail-Over verursachte Downtime endet.
Es lohnt sich durchaus, die Frage zu stellen, ob es im Falle eines Falles tatsächlich eine Datenbank braucht, bei der unter allen Umständen sicher ist, dass niemals auch nur ein einzelner Eintrag verloren geht. Es stehen sich zwei grundlegende Betriebsmuster gegenüber: Eine Fail-Over-Lösung wie oben beschrieben, die tatsächlich "transaction safe" ist, also vor Datenverlust im Falle eines Ausfalls schützt ( Abbildung 3 ). Ist es andererseits denkbar, dass im Rahmen eines Ausfalls eines Servers einzelne Records verloren gehen, ist die Situation entspannter. Beispiele aus der Praxis sind Webstores oder Foren: Hier können Admins es meistens eher verschmerzen, dass Einträge verloren gehen, die kurz vor dem Crash erstellt worden sind, als dass eine Datenbank wegen InnoDB-Recoverys 20 oder mehr Minuten gar nicht zur Verfügung steht.
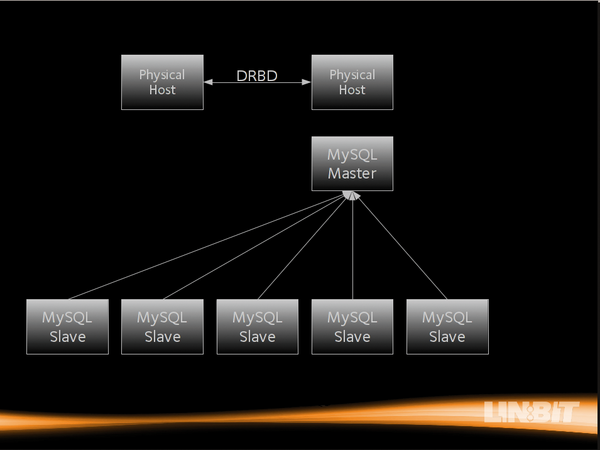 Abbildung 3: Dieses Setup ist ein klassisches MySQL-Setup, das zwar nie einen Eintrag verliert, möglicherweise aber beim Fail-Over sehr lange braucht.
Abbildung 3: Dieses Setup ist ein klassisches MySQL-Setup, das zwar nie einen Eintrag verliert, möglicherweise aber beim Fail-Over sehr lange braucht.
Beide Szenarien lassen sich mit Pacemaker abbilden. Die sichere Lösung war im Rahmen dieses Artikels bereits Thema – das berühmte Schema F mit einem von Pacemaker verwalteten MySQL auf DRBD. Aber auch die Variante 2 lässt sich mit Pacemaker realisieren. Auch für diese Variante braucht es mindestens zwei Server. Der Unterschied zur Standard-Variante: Durch die Möglichkeit, dass einzelne Datensätze verloren gehen, erkauft sich der Admin die Möglichkeit des nahezu sofortigen Fail-Overs ohne lange Wartezeit. Denn in diesem Szenario gibt es einen MySQL-Master und einen MySQL-Slave, die ihren Inhalt auf MySQL-Ebene permanent synchron halten. Fällt der aktuelle Master aus, "befördert" pacemaker den verbliebenen Knoten vom Slave zum Master ( Abbildung 4 und 5 ). So steht sofort ein neuer Masterserver zur Verfügung. Anstelle von DRBD kommt in diesem Szenario also vor allem die in MySQL vorhandene Replikationsfunktion zum Einsatz.
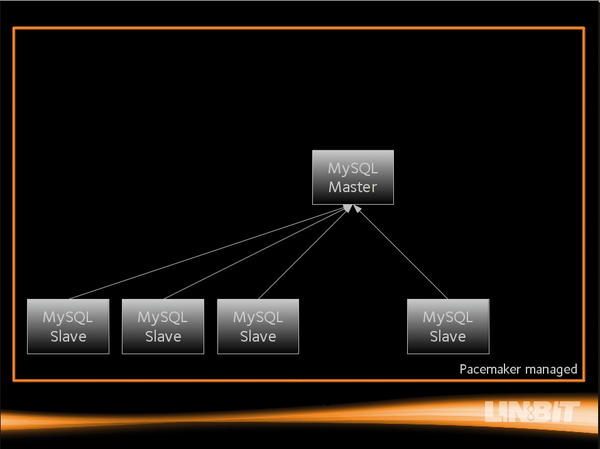 Abbildung 5: … und verliert dabei möglicherweise einzelne Einträge, bietet dafür aber nahezu sofortigen Fail-Over.
Abbildung 5: … und verliert dabei möglicherweise einzelne Einträge, bietet dafür aber nahezu sofortigen Fail-Over.
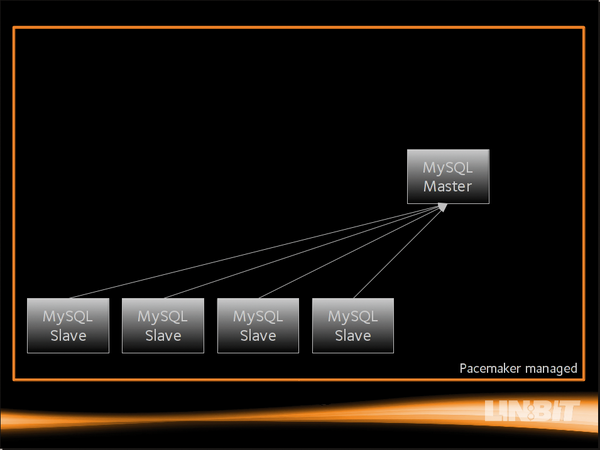 Abbildung 4: In diesem Szenario kommen hingegen dynamische MySQL Master und Slaves zum Einsatz. Stirbt ein Master-Server, übernimmt ein anderer die Rolle …
Abbildung 4: In diesem Szenario kommen hingegen dynamische MySQL Master und Slaves zum Einsatz. Stirbt ein Master-Server, übernimmt ein anderer die Rolle …
Dieses Szenario ist nicht auf zwei Server beschränkt, sondern kann letztlich aus beliebig vielen MySQL-Slave-Servern bestehen. Pacemaker hilft bei der Administration: Mittels
»clone«
-Ressourcen weiß es zu jedem Zeitpunkt, auf welchen Mitgliedern eines Clusters ein MySQL läuft und welche Rolle – Master oder Slave – dieses MySQL gerade hat. Fällt der aktuelle Master-Server aus, befördert Pacemaker automatisch einen anderen Slave zum Master. indem eine Service-IP jeweils mittels
»Colocation-Constraint«
auf den Rechner fixiert wird, auf dem auch die aktuelle Master-Instanz von MySQL läuft. So gibt es immer ein funktionierendes MySQL, das auf der definierten IP-Adresse lauscht.
Die genaue Beschreibung eines Master-Slave-Setups mit Pacemaker und MySQL hätte den Rahmen dieses Artikels gesprengt. Wer Interesse an einem solchen Setup hat, richtet zunächst zwei MySQL-Datenbanken mit Replikation ein – eine Anleitung dazu findet sich in der Doku von MySQL unter
[1]
. Anschließend fehlt noch die passende Konfiguration für Pacemaker, die auf der Wiki-Seite des
»mysql«
-OCF-RAs unter
[2]
zu finden ist.
Aktiv-Aktiv-MySQL-Setup
Infos
- MySQL-Replikation einrichten: http://dev.mysql.com/doc/refman/5.5/en/replication-howto.html
- Master-Slave-Konfiguration von MySQL in Pacemaker: http://www.linux-ha.org/wiki/Mysql_(resource_agent)
- Admin-Magazin 5/11, Seite 80
- Martin Loschwitz: Storage für HA-Cluster
- DRBD Quick Reference Guide: http://www.linbit.com/en/education/tech-guides/drbd-quick-reference/
- Pacemaker Quick Reference Guide: http://www.linbit.com/en/education/tech-guides/pacemaker-quick-reference/
- Andrew Beekhof, Cluster from Scratch: http://theclusterguy.clusterlabs.org/post/193226662/clusters-from-scratch
Ähnliche Artikel





Mit Pacemaker Dienste hochverfügbar betreiben
Konfigurationsmanagement

Themen


