
Dateisystemfragen
Für dedizierte PostgreSQL-Datenbankserver wird meistens Linux als Betriebssystem verwendet. Dabei gilt es, ein paar Einstellungen und Optimierungen zu beachten, um die beste Leistung herauszukitzeln. Ältere Linuxsysteme nutzen meist als Dateisystem Ext3, das ist zwar zuverlässig, aber nicht das schnellste. Ext4 ist schneller, aber für PostgreSQL noch nicht gut genug ausgetestet. Bleibt als guter Kompromiss XFS. Das ist sehr stabil und gleichzeitig recht schnell. Bei allen Dateisystemen ist die Nutzung des Mount-Parameters
»noatime«
von Vorteil. Er deaktiviert das Anpassen der Information, wann auf eine Datei zum letzten Mal zugegriffen wurde – für Datenbanken ist das normalerweise nicht von Bedeutung. Wird Hardware mit batteriegestütztem Write Cache eingesetzt, dann brauchen sowohl XFS als auch Ext4 die Mountoption
»nobarrier«
, um damit schnell zu sein. Hiermit wird die Kontrolle des Dateisystems darüber abgestellt, ob der Platten- oder Controller-Cache geleert ist. Es ist ratsam, diesen Job der Hardware zu überlassen.
Um eine gute Lesegeschwindigkeit bei sequenziellen Tabellenscans über große Tabellen zu erhalten, ist PostgreSQL auf das Read-Ahead des Betriebssystems angewiesen. Linux hat eine hervorragende Read-Ahead-Implementierung, aber voreingestellt ist meist eine viel zu kleine Anzahl an Blöcken (256). Ein guter Anfangswert sind 4096 Blöcke. Das lässt sich wie folgt ändern:
/sbin/blockdev --setra 4096 /dev/sda
An der Schreibfront erwartet PostgreSQL, dass das Betriebssystem normale Schreibaktionen zwischenspeichert und sie nur dann auf der Festplatte ausführt, wenn der Checkpoint erreicht ist. Die Größe des Write Cache war mit alten Linux-Kerneln (vor 2.6.22) erheblich zu groß. Der neue Vorgabewert kann in alten Kerneln durch folgende Befehle eingestellt werden:
echo 10 > /proc/sys/vm/dirty_ratio echo 5 > /proc/sys/vm/dirty_background_ratio
Damit wird erlaubt, dass 10 Prozent des RAMs für einen einzelnen Prozess als Write Cache verwendet werden. Wenn 5 Prozent geänderte Daten im Write Cache liegen, wird der Auslagerungsprozess angestoßen. Die Werte können bei Systemen mit vielen Gigabyte RAM immer noch zu hoch sein. Seit Linux-Kernel 2.6.29 lassen sich die Werte unter Verwendung von
»dirty_background_bytes«
und
»dirty_bytes«
noch niedriger setzen. Anzumerken ist hier, dass einige Massenoperationen in PostgreSQL, besonders
»VACUUM«
, durch eine zu starke Reduzierung des Linux-Write-Cache signifikant langsamer werden können.
Monitoring
PostgreSQL kümmert sich weder darum, wie das Betriebssystem Read-Ahead oder Write-Caching ausführt, noch verfolgt es, was auf der Hardware passiert. Eine separate Überwachung des Systems ist deshalb wärmstens zu empfehlen. Am besten durch eine Anwendung zur Trendermittlung. Wichtig sind hier vor allem Trends der CPU-Aktivität, Speicherverbrauch, Plattenauslastung und Datenbankstatistiken. Die beiden gängigsten Open-Source-Pakete, die diese Anforderungen erfüllen, sind Munin und Cacti. Munin lässt sich leichter aufsetzen und beinhaltet mehr Einblicke in PostgreSQL-Interna. Munins größter Nachteil ist, dass es bei der Datensammlung einer großen Anzahl von Servern nicht mehr allzu gut skaliert. Wie ein typischer Trendgraph der Datenbankstatistiken in Munin aussieht, zeigt die Abbildung 3 .
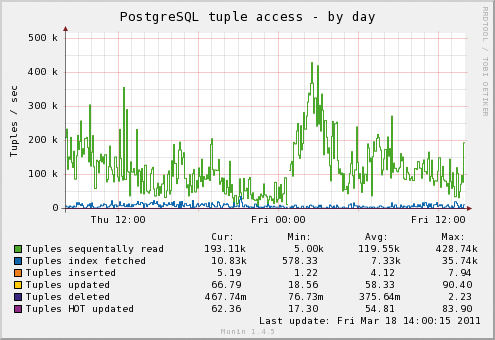 Abbildung 3: Mit Munin lassen sich relativ einfach Graphen darstellen, aus denen ein Trend ablesbar ist. Dieser zeigt Zugriffe auf Datenbanktupel im Tagesverlauf.
Abbildung 3: Mit Munin lassen sich relativ einfach Graphen darstellen, aus denen ein Trend ablesbar ist. Dieser zeigt Zugriffe auf Datenbanktupel im Tagesverlauf.
Abgebildet ist ein Server, bei dem die meisten Zugriffe auf Datenzeilen (intern Tuple genannt) sequenzielle Scans erfordern. In diesem Beispiel ist das kein Problem, da viele der Tabellen zu klein sind, als dass die Verwendung von Indizes sinnvoll wäre. Allerdings ist es für das Erkennen von Problemen im Zusammenspiel mit dem Server und der Anwendung extrem wichtig, die Unterschiede zwischen den Statistiken von Index- gegenüber sequenziellen Zugriffen zu sehen.
PostgreSQL kommt sehr gut mit einer Vielfalt an Geschwindigkeitsanforderungen zurecht. Aber es ist nur eine Komponente des Baukastens, der auch das Betriebssystem und Zusatzsoftware von Connection-Pooling bis hin zur Trendermittlung enthält. Den Server zu tunen, ist wichtig. Geschwindigkeitsüberwachung, das Lesen der Datenbank-Logs und die Abstimmung des Datenbankdesigns sind entscheidend, um das gute Geschwindigkeitsniveau auch dann noch zu halten, wenn die Datenbank wächst. (jcb )
Ähnliche Artikel




PostgreSQL oder MySQL: Wer skaliert besser?
Konfigurationsmanagement

Themen


