
Verfügbarer Speicher
Jede Verbindung kann eine bestimmte Menge Arbeitsspeicher zur Ausführung von Queries nutzen. Hauptsächlich werden hier zu sortierende Daten und Hash-Tabellen abgelegt, die sowohl zum Verknüpfen von Tabellen als auch zur Umsetzung von Klauseln wie
»GROUP BY«
verwendet werden. Der Wert wird mit
»work_mem«
festgelegt. Zu bedenken ist, dass der Parameter einschränkt, wie viel Speicher jede einzelne Sortier- oder Hashoperation nutzt; einzelne Queries können durchaus mehrere dieser Operationen beinhalten. Das heißt, jede Verbindung kann in Summe ein Vielfaches an
»work_mem«
nutzen. Ein guter Startwert für work_mem ist:
»RAM/(max_connections * 16)«
. Da der Wert von der Komplexität der Queries abhängt, kann er bei einfachen Queries eventuell sogar um das Vierfache erhöht werden. Die Variable
»work_mem«
lässt sich im laufenden Betrieb ändern. Getunte Server haben
»work_mem«
meist auf einen Wert zwischen 4 und 128 MByte gesetzt. Es ist in der Praxis durchaus üblich, den Wert für ein einzelnes, sehr aufwendiges Query signifikant (bis zu 2 GByte) zu erhöhen.
Random I/O und Logs
Festplattenköpfe sind deutlich schneller beim Datenlesen, wenn die Daten direkt hintereinander auf der Platte liegen, als wenn sie chaotisch hin- und herspringen müssen, um die Daten zu finden. Der Parameter
»random_page_cost«
gibt der Datenbank eine ungefähre Vorstellung, um wie viel langsamer das Lesen zufällig verteilter Daten ist. Voreingestellt ist hier der Faktor 4.0. Der Wert sollte nicht auf den tatsächlichen Unterschied gesetzt werden, sondern wird in der Praxis häufig auf einen weitaus kleineren Wert eingestellt. Der Grund dafür ist, dass die meisten der gängigen, zufällig verteilten Daten (etwa sehr häufig genutzte Indexe) sowieso bereits im RAM liegen. Es ist durchaus üblich, auf schnellen Systemen beziehungsweise auf Systemen mit viel Arbeitsspeicher den Wert für
»random_page_cost«
auf 2.0 zu setzen. Wenn sicher ist, dass die gesamte Datenbank oder große Teile von ihr im RAM zwischengelagert werden, kann der Tuner
»random_page_cost«
sogar auf einen sehr kleinen Wert wie 1.01 setzen.
PostgreSQL unterstützt das Protokollieren einer Vielzahl von Informationen. Viele Optionen sind anfangs abgeschaltet. Es ist ratsam, zu Beginn alle Queries und auch
»autovacuum«
-Prozesse, die länger als eine Sekunde dauern, im Log festzuhalten. Wenn das zu unübersichtlich wird, lässt sich die Zeit erhöhen, die der Prozess mindestens laufen muss. Bei der Analyse der Protokolldateien kommen meist externe Tools zum Einsatz. PgFouine ist gut für kleine und mittlere Log-Dateien. Um die Protokollierung für die häufigsten Bremser einzuschalten und sie auf die Analyse mit PgFouine (
Abbildung 1
) vorzubereiten, bedarf es der folgenden Anpassung in
»postgresql.conf«
:
log_line_prefix='%t[%p]:[%l-1] user=%u,db=%d' log_min_duration_statement=1s log_autovacuum_min_duration=1s log_temp_files=0 log_checkpoints=on log_lock_waits=on
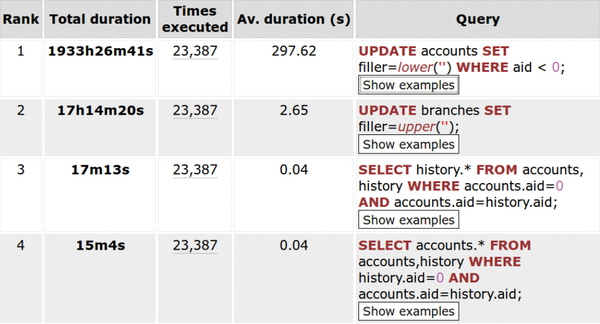 Abbildung 1: Der Logfile-Analyzer PgFouine entlarvt hier lang laufende Queries.
Abbildung 1: Der Logfile-Analyzer PgFouine entlarvt hier lang laufende Queries.
Ähnliche Artikel




Konfigurationsmanagement

Themen


