Pakete filtern
Der Linux-Kernel und üblicherweise auch die BSD-Kernel bieten daher die Möglichkeit, Pakete direkt im Kernel zu filtern. Programme aus dem Userspace, die PF_PACKET verwenden, können hierfür einen so genannten Berkeley Packet Filter an den jeweiligen Socket binden, welcher auf einer virtuellen Maschine im Kernel läuft (siehe Abbildung 3). Diese virtuelle Maschine interpretiert die zur Verfügung gestellten Filter-Programme und wendet sie immer wieder auf eintreffende Pakete an. Sie kann als ein abgeschlossenes System betrachtet werden, das ähnlich wie eine CPU Akkumulator und Register besitzt und auf dem Strom der Netzwerkpakete arbeitet. Unter »net/core/filter.c« findet sich die Funktion »sk_run_filter()«, die sich auf die »sk_buff Struktur« (und damit das Paket) anwenden lässt.
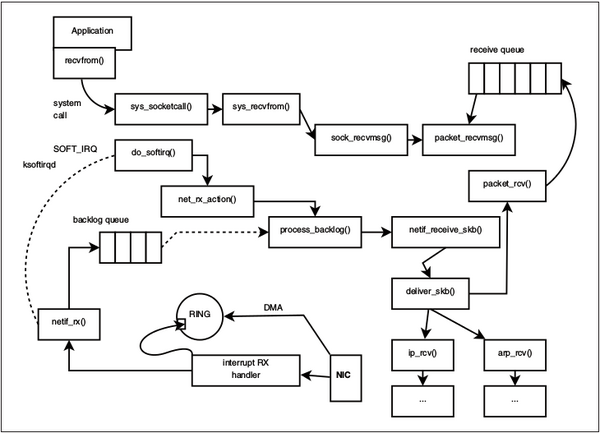 Abbildung 3: Pfad eines Netzwerkpakets von der Network Interface Card (NIC) zur Monitoring-Applikation unter Verwendung von recvfrom(2) …
Abbildung 3: Pfad eines Netzwerkpakets von der Network Interface Card (NIC) zur Monitoring-Applikation unter Verwendung von recvfrom(2) …
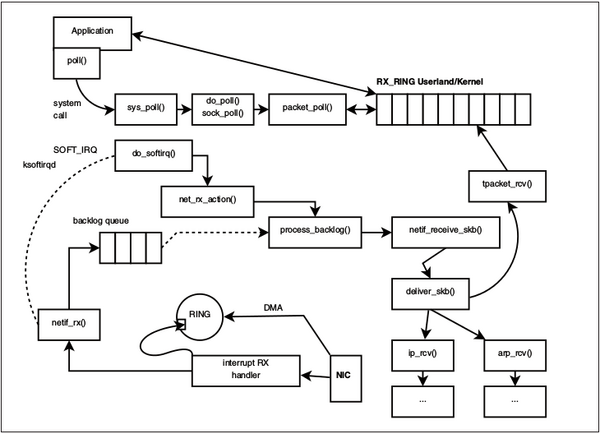 Abbildung 4: … sowie bei Verwendung vom RX_RING. Letzteres vermeidet Kontextwechsel und Kopieroperationen und ist daher sehr viel perfomanter.
Abbildung 4: … sowie bei Verwendung vom RX_RING. Letzteres vermeidet Kontextwechsel und Kopieroperationen und ist daher sehr viel perfomanter.
Paketfilter schreiben
Wie sieht nun die Sprache aus, in der sich die bereits erwähnten Berkeley Packet Filter beschreiben lassen? Der Sniffer liefert unter »/etc/netsniff‑ng/rules« einige Beispielprogramme, die man in Verbindung mit der »‑‑filter«-Option direkt ausprobieren kann. Eigene Filter zu schreiben ist nicht ganz so einfach, verschafft einem jedoch volle Kontrolle über jedes einzelne Byte des Netzwerkpakets.
Der Berkeley Packet Filter (BSD Packet Filter), wurde von Steven McCanne und Van Jacobsen eingeführt. Für gewöhnlich werden beim Filtern mehr Pakete verworfen als akzeptiert, daher bestimmt der Paketfilter auch die Gesamtperformance des Systems wesentlich mit.
Wer schon für »tcpdump« Filter entwickelt hat oder findet, dass dessen Beschreibungssprache leichter zu handhaben ist, der kann auf einen Compiler zurückgreifen, der TCP-Dump-Filter in die RISC-ähnliche BPF-Syntax übersetzt. Die TCP-Dump-Option »‑dd« wandelt dabei den Eingabestring in die entsprechende Syntax um. Standardmäßig haben jedoch die durch »tcpdump« erzeugten Filterprogramme den Nachteil, dass sie Pakete ab Byte 96 (0x60) einfach abschneiden. Näheres darüber ist im Blog von netsniff-ng nachzulesen [2].
Fortgeschrittene Nutzer, die volle Kontrolle über den Filterprozess gewinnen möchten, können auch eigene Programme entwickeln. Dabei hilft es, die im Folgenden erläuterte Syntax und Funktionsweise von BPF zu verstehen.
Die virtuelle BPF-Maschine im Kernel besteht aus einem Akkumulator, einem Index-Register (im Weiteren auch als X bezeichnet), einem Scratch-Memory-Store (ein Register zum temporären Speichern von Daten) und einem Programmzähler. Die Operationen der Maschine lassen sich in verschiedene Kategorien einteilen:
- Load-Instruktionen kopieren entweder einenWert in den Akkumulator oder in das IndexRegister. Das kann entweder ein fester Wertsein oder ein Wert, der mit einem einemfesten oder variablen Offset aus einem Netzwerkpaket stammt, oder ein Wert aus demScratch-Memory-Store.
- Store-Instruktionen kopieren entweder denAkkumulator oder das Index-Register in denScratch-Memory-Store.
- ALU-Instruktionen führen arithmetischeoder logische Operationen auf dem Akkumulator durch. Das Index-Register oder einebeliebige Konstante dient als Operand.
- Branch-Instruktion steuern den Kontrollfluss. Sie basieren beispielsweise auf einemVergleich zwischen einer Konstante oder demIndex-Register mit dem Akkumulator.
- Return-Instruktionen terminieren das Filter-Programm. Dabei bestimmt der Rückgabewert, wieviel Byte des Paketes in höhereSchichten weiterzureichen sind. Bei »0« wirddas Paket verworfen.
- Misc-Instruktionen umfassen alles andere.
Zurzeit betrifft das den Datentransfer zwischen Registern. Das Befehlsformat definiert sich wie folgt:
+‑‑‑‑‑‑‑‑‑‑‑+‑‑‑‑‑‑+‑‑‑‑‑‑+‑‑‑‑‑‑+ | opcode:16 | jt:8 | jf:8 | k:32 | +‑‑‑‑‑‑‑‑‑‑‑+‑‑‑‑‑‑+‑‑‑‑‑‑+‑‑‑‑‑‑+
Das Feld »opcode« gibt dabei die Instruktion sowie Adressierungsart an. »jt« sowie »jf« werden bei bedingten Sprüngen verwendet und geben jeweils die Sprung-Offsets zum nächsten Befehl an, abhängig davon, ob die Auswertung true oder false liefert. Das 32-Bit breite Feld »k« ist ein generisches Feld und wird für verschiedene Zwecke verwendet. Der Linux-Kernel hat diese Struktur in »linux/filter.h« adaptiert (Listing 2).
Listing 2: »linux/filter.h«
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
struct sock_fprog { /* Required for SO_ATTACH_FILTER. */
unsigned short len; /* Number of filter blocks */
struct sock_filter __user *filter;
};
Üblicherweise stellt der Filter dabei eine Aneinanderkettung von »sock_filter«-Strukturen dar, die mit einer zusätzlichen Komponente zur Längenprüfung in Verbindung gebracht werden. Die Instruktionen selbst kommen typischer Assemblersyntax nah. Die jeweiligen Befehlsklassen ähneln dabei der erwähnten Befehlskategorisierung (Tabelle 1).
Tabelle 1. Befehlsklassen der BPF -Maschine
|
Opcode |
Nummer |
Funktion |
|---|---|---|
|
LD |
0x00 |
Copy indicated value into accumulator |
|
LDX |
0x01 |
Copy indicated value into index register |
|
ST |
0x02 |
Copy accumulator value into the scratch memory store |
|
STX |
0x03 |
Copy index register value intothe scratch memory store |
|
ALU |
0x04 |
Perform arithmetic or logic operation on the accumulator |
|
JMP |
0x05 |
Perform a branch instruction |
|
RET |
0x06 |
Return/exit from filter program |
|
MISC |
0x07 |
Data transfer between index register and accumulator |
Zusätzlich zur Angabe der Befehlsklassen existieren noch klassenspezifische Teile des Opcodes, die der Anwender üblicherweise mittels bitweisem OR zusammenfügt (LD/LDX-spezifische Felder). ALU- beziehungsweise JMP-Befehle führen die spezifizierte Operation mittels Akkumulator und Operand (Konstante oder Index-Register) aus und speichern ihr Ergebnis wieder in den Akkumulator zur weiteren Verarbeitung. Der Sprung geschieht dabei zu einem Offset von der aktuellen Instruktion zu »jt+1« beziehungsweise »jf+1«. Eine Division durch Null terminiert jedoch das Filterprogramm.
Das Index-Register selbst ist nicht dazu in der Lage, Daten direkt aus einem Paket zu laden, sondern muss sich den Wert über einen Umweg holen. Dazu lädt es den Wert zunächst in den Akkumulator und transferiert ihn von dort mittels »tax«-Operation in das Index-Register. Zu erwähnen ist außerdem, dass das Index-Register auch dazu taugt, den IP-Header zu parsen, der direkt mittels »4*([k]&0xf)«-Adressierung ins Register ladbar ist. Die erwähnte »tax«-Operation unde ihre Umkehrung sind so definiert:
TAX 0x00 Transfer value from accumulator into index register TXA 0x80 Transfer value from index register to accumulator
Ähnliche Artikel




Konfigurationsmanagement

Themen


