WAL spielt Schlüsselrolle
Replikationsprojekte für PostgreSQL gibt es schon geraume Zeit. Aus dem Bereich der Trigger-basierten Lösungen stammt Slony-I [1], der stärkste Vertreter aus der Gruppe der Middleware-Lösungen ist dagegen PGPool-II [2]. Beide Projekte sind allerdings für das Gros der Installationen zu komplex und zu wartungsintensiv. Aus diesem Grund wurde schon im Jahr 2005 mit PostgreSQL 8.0 an der grundlegenden Infrastruktur für einen nativen Replikationsmechanismus gearbeitet. Um ihn zu verstehen ist allerdings eine Beschäftigung mit dem Write Ahead Log von PostgreSQL unumgänglich. PostgreSQL muss aufgrund der ACID-Constraints [3], denen alle SQL-konforme Datenbanken unterworfen sind, garantieren können, dass Transaktionen die erfolgreich commitet wurden, auf jeden Fall erhalten bleiben, selbst wenn Sekundenbruchteile nach dem »commit« ein Stromausfall eintreten würde. Um das gewährleisten zu können, werden alle Änderungen von erfolgreich abgeschlossen Transaktionen synchron auf die Platte geschrieben. Nun wäre es aber nicht effektiv, dabei die betroffenen Tabellen und Indizes direkt zu ändern, denn das würde zu vielen über die ganze Platte verteilten Schreiboperationen führen. Deshalb erfand man das Write Ahead Log, kurz WAL.
Alle Änderungen an Datenbankdateien landen zuerst im Write Ahead Log, das PostgreSQL in 16 MByte-Segmente unterteilt und sequentiell beschreibt. Durch die damit erreichbare hohe Lokalität der Änderungen, sind synchrone Operationen in diesem Log deutlich ressourcenschonender als direkte Schreibzugriffe. Das WAL ist im Normalbetrieb ein reiner Durchlaufspeicher, Änderungen aus Transaktionen werden kontinuierlich sequentiell an das Log angehängt, andere Prozesse in der Datenbank sorgen dafür, dass diese Änderungen auch in die Table- und Indexdateien, kurz Heap-Dateien, übernommen werden.
In regelmäßigen Abständen setzt PostgreSQL einen Checkpoint, der alle ausstehenden Änderungen bis zu diesem Zeitpunkt in die Heap-Dateien übernimmt. Danach kann die Datenbank alle WAL-Segmente, die vor dem Checkpoint angefallen sind, recyclen oder löschen, sie werden für den sicheren Betrieb nicht mehr benötigt. Sollte es zu einem Absturz der Datenbank durch Stromausfall, Crash, unsauberen Neustart oder Ähnliches kommen, sucht die Datenbank beim nächsten Start den Punkt des letzten erfolgreichen Checkpoints und spielt dann alle im WAL vermerkten Änderungen noch einmal ab, egal ob diese schon einmal übernommen worden sind oder nicht. Nach dem Recovery kann PostgreSQL wieder garantieren, dass die Datenbank denselben Zustand hat wie vor dem Absturz.
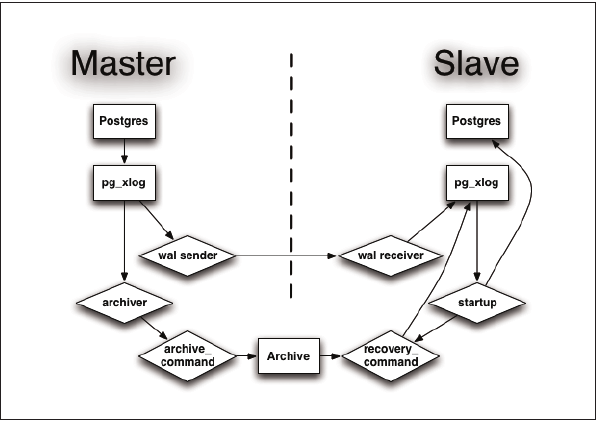 Abbildung 1: Das Architekturdiagramm veranschaulicht den Log-Transfer bei der Master-Slave-Replikation in PostgreSQL 9.0.
Abbildung 1: Das Architekturdiagramm veranschaulicht den Log-Transfer bei der Master-Slave-Replikation in PostgreSQL 9.0.
Log Shipping
Da im Write Ahead Log alle Änderungen der Datenbank bereits vermerkt sind, eignet es sich auch perfekt als Quelle für mögliche Replikationsvarianten. In PostgreSQL 8.0 wurde ein Mechanismus vorgestellt der unter dem Namen Log Shipping bekannt ist. Beim Log Shipping werden vom Master abgeschlossene Logfile-Segmente über ein vom Anwender definierbares Shell-Kommando (Archive Command) kopiert. Die Varianten reichen hierbei von einem normalen »cp« auf einem NFS-Mount über »scp« bis »rsync«.
Mit diesen archivierten WAL-Segmenten sowie einer Sicherung des PostgreSQL-Datenverzeichnisses (kurz: Base Backup) lässt sich wieder eine lauffähige Datenbank herstellen. Log Shipping war also primär als Backup-Mechanismus gedacht; in Umgebungen wo komplette Datenbankdumps zu groß oder zu ineffizient waren, ließ sich mit Log Shipping und einer vorkonfigurierten Recovery Umgebung eine Alternative zu periodischen Komplettsicherungen schaffen. Ein weiteres interessantes Feature das durch Log Shipping ermöglicht wurde, war das Point-InTime-Recovery. PITR ermöglichte es Datenbankadministratoren, mit einem Base Backup und allen angefallenen WAL-Segmenten einen beliebigen Punkt in der Datenbankhistorie (ab dem Backup) transaktionsgenau wiederherzustellen. Jeder, der bei einem »update« oder »delete« schon mal die Where-Bedingung vergessen hat, weiß diese Funktionalität zu schätzen.
Ähnliche Artikel
-
Bucardo 5.0 repliziert Datenbanken flexibler
Die neue Version der Datenbank-Replikationssoftware Bucardo ist nicht länger auf zwei Datenbanken beschränkt und kann außer mit PostgreSQL auch mit anderen SQL-Datenbanken umgehen.
-
Systeme: PostgreSQL 9.4

-
PostgreSQL 10 ist fertig
Die neue Version der freien SQL-Datenbank beschert Usern signifikante Verbesserungen.
-
PostgreSQL 9.1 veröffentlicht
Die PostgreSQL Global Development Group gibt die Verfügbarkeit einer neuen Version ihrer Datenbank, PostgreSQL 9.1, bekannt.
-
Hochverfügbarkeit und Replikation für PostgreSQL

Konfigurationsmanagement

Themen


