Backup und Recovery bei Datenbanken: Woran man denken sollte

Rettungsübung

Gerade in einer größeren Umgebung stellt die vollständige Wiederherstellung einer Datenbank oft eine Herausforderung dar, die zudem nicht wenig Zeit beansprucht. Die richtige Planung des Datenbank-Backups ist dabei ein wesentlicher Faktor, um Zeit zu sparen und die Kosten einer ungeplanten Downtime zu minimieren. Unabhängig von der Hardware spielen die folgenden Fragen eine wichtige Rolle bei der Planung des Backups:
- Wie stark belastet das Backup das System?
- Wie lange dauert ein vollständiges Backup?
- Wie groß darf der Datenverlust maximal sein (Recovery Point Objective – RPO)?
- Wie lange dauert ein Recovery? Wie lange darf ein System oder Prozess stillstehen (Recovery Time Objective – RTO)?
- Was muss neben Standard-Backups noch beachtet werden?
- Wie validiere ich die Vollständigkeit und Funktionsweise nach der Wiederherstellung?
- Wie sicher ist die gewählte Backup-Variante?
Qual der Wahl
Um Datenverlust und Systembelastung entgegenzuwirken, ist vor allem die richtige Wahl der Backup-Variante ausschlaggebend. Je nach Anwendungsfall muss man sich entscheiden, ob man physische oder logische Backups bevorzugt oder auch beides zeitgleich benutzen möchte. Grundlegend unterscheiden sich die beiden Varianten vor allem in der Größe und Dauer der jeweiligen Backups. Gerade das ist meist ausschlaggebend dafür, wie viel I/O und Netzwerklast durch das Backup verursacht wird.
Beim physischen Ansatz werden die Daten von den Platten blockweise auf ein Sicherungsmedium kopiert (Binary Backup). Diese Backup-Variante benötigt nicht zwangsweise eine Verbindung zur Datenbank und belastet das System anders als ein logisches Backup.
Wichtig: Werden physische Backups bei laufender Datenbank angefertigt, sind sie zwangsläufig nicht konsistent. Um bei der Wiederherstellung zu einem konsistenten Stand zu gelangen, muss der Datenbank bekannt sein, welche Änderungen während und nach dem Backup angefallen sind. Diese Information speichern Datenbanken üblicherweise in Logdateien, die ebenfalls archiviert werden (Beispiele: PostgreSQL, SQLite – WAL (Write-Ahead-Log), Oracle – Redo Logs). Bei der Wiederherstellung werden die archivierten Logdateien eingespielt, wodurch letztendlich ein konsistenter Stand erreicht wird. Die Wiederherstellung kann auch nur bis zu einem bestimmten Zeitpunkt erfolgen (Point-In-Time-Recovery, PITR) – das ist vor allem bei Benutzerfehlern ein wichtiges Mittel, um Daten zu retten.
Diese Möglichkeit ist oft auch die Grundlage für Standby-Datenbanken, die kontinuierlich im Recovery-Modus laufen und die anfallenden Logdateien immer wieder einlesen ( Abbildung 1 ). Generell gilt: Umso mehr dieser Änderungen eingespielt werden müssen, desto länger dauert es, den gewünschten Datenstand zu erreichen.
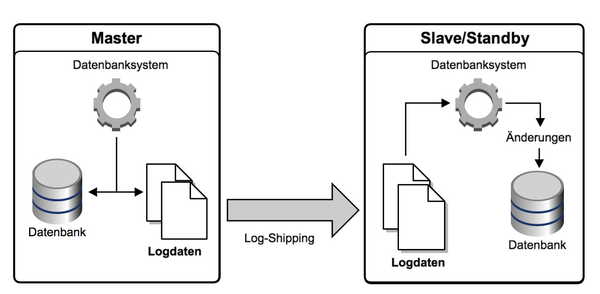 Abbildung 1: Standby-Datenbanken führen die Logs ihrer Master-Datenbank kontinuierlich nach.
Abbildung 1: Standby-Datenbanken führen die Logs ihrer Master-Datenbank kontinuierlich nach.
Logische Backups haben dagegen den Vorteil, dass damit auch partielle Backups möglich sind, bei denen zum Beispiel nur bestimmte Tabellen gesichert werden. Beim logischen Backup werden generell anstelle von Plattensektoren Datenbankobjekte mit ihrem Inhalt und relationalem Zusammenhang gesichert. Zudem werden im Gegensatz zu physischen Backups keine Indexdaten archiviert, sondern nur die Statements, die zum Anlegen der Indizes notwendig sind – was Backups zwar wesentlich kleiner macht, aber beim Wiederherstellen viel Zeit kostet.
Bei Datenbanksystemen mit Multiversion Concurrency Control (MCC oder MVCC) kann sich im Laufe der Zeit unverwendeter Platz in der Datenbank ansammeln (Bloat oder Garbage genannt). Die Wiederherstellung größerer Datenbanken profitiert daher oftmals von logischen Backups, weil bei ihnen große Teile dieses unverwendeten Platzes nicht gesichert werden. Physische Backups, die genaue 1:1-Kopien des Originals sind, beziehen diesen Platz dagegen ein.
Eine weitere Überlegung betrifft inkrementelle Backups. Man unterscheidet dabei zwischen differenziellen- und kumulativen Backups. Differenzielle Backups bauen seit dem letzten Voll-Backup beziehungsweise dem letzten differenziellen Backup aufeinander auf ( Abbildung 2 ), wogegen kumulative Backups sämtliche Änderungen seit dem letzten Voll-Backup enthalten. Hierbei wird das Backup mit wachsendem Zeitabstand immer umfangreicher, allerdings braucht man dafür nur das jüngste aufzubewahren ( Abbildung 3 ). Inkrementelle Backups wirken sich auch wesentlich auf die Wiederherstellungsdauer aus, da man im Falle eines Crashs zuerst ein Voll-Backup und anschließend sämtliche inkrementellen Backups bis zum gewünschten Zeitpunkt einspielen muss.
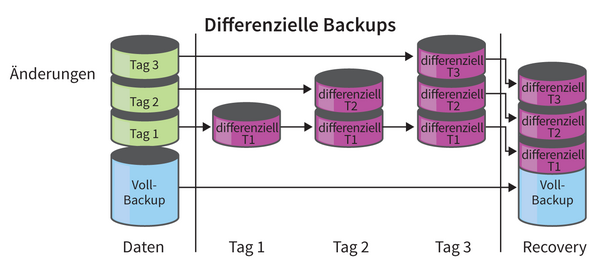 Abbildung 2: Das Prinzip differenzieller Backups: Beim Recovery muss man alle Vorläufer in richtiger Reihenfolge einspielen. Dafür bleibt jedes Backup klein.
Abbildung 2: Das Prinzip differenzieller Backups: Beim Recovery muss man alle Vorläufer in richtiger Reihenfolge einspielen. Dafür bleibt jedes Backup klein.
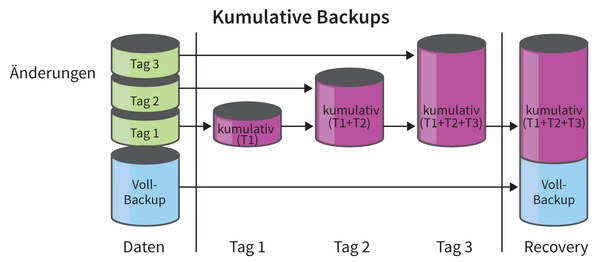 Abbildung 3: So funktionieren kumulative Backups: Sie wachsen stetig, dafür braucht man immer nur das Letzte.
Abbildung 3: So funktionieren kumulative Backups: Sie wachsen stetig, dafür braucht man immer nur das Letzte.
Jedes Datenbanksystem verfolgt beim Thema Backup unterschiedliche Ansätze. PostgreSQL
[1]
bringt beispielsweise erst ab Version 9.1.X das
»pg_basebackup«
-Tool mit, das physische Backups und Replikation erleichtert, kennt jedoch noch keine Umsetzung von inkrementellen oder differenziellen Backups. Bei Oracle
[2]
hingegen kann man via RMAN (Oracles Recovery Manager) sowohl Voll-Backups als auch inkrementelle Backups ziehen.
Replikation bei Datenbanken
Um mehr Ausfallsicherheit zu erzielen, gibt es auch die Möglichkeit der kontinuierlichen (synchronen oder asynchronen) Datenbank-Replikation. Manche Systeme erlauben es, eine Standby-Datenbank etwa über die zuvor erwähnten Logdateien auf aktuellem Stand zu halten. Eine so aufgesetzte Standby-Datenbank befindet sich ununterbrochen im Wiederherstellungsmodus und versucht dauerhaft einlaufende Änderungen bei sich nachzuziehen.
Hot-Standby-Instanzen können darüber hinaus verwendet werden, um lesende Prozesse (etwa ein Reporting oder wiederum Backups) auszulagern und somit I/O- und CPU-Last zu verteilen, sprich eine Art von Loadbalancing zu erreichen.
Falls es zu einem Problem bei der Master-Instanz kommen sollte, kann man später die Standby-Datenbank zum Master ernennen (promoten) und erspart sich dadurch das erneute Aufsetzen einer Datenbank samt Wiederherstellung der Daten, woraus eine große Zeitersparnis resultieren kann. Allerdings besteht der nächste logische Schritt dann natürlich darin, wieder eine Standby-Instanz aufzusetzen, damit die neu ernannte Master-Instanz nicht die komplette Schreib- und Leselast verarbeiten muss. Daraus lässt sich ableiten, dass Standby-Systeme auch Hardware-seitig hierfür ausgelegt sein müssen, die komplette anfallende Systemlast zu schultern.
Im Zuge eines Failovers müssen auch die eingehenden Verbindungen auf die mittlerweile als Master-Instanz betriebene ehemalige Standby-Datenbank umgeleitet werden. Dies kann sowohl via Cluster-Manager (etwa via Pacemaker [3] und Corosync [4] ), aber auch mit Bordmitteln und/oder Middleware passieren.
Im Falle eines versehentlich abgesetzten Statements – etwa eines UPDATE ohne WHERE-Klausel oder eines TRUNCATE am falschen Host – kann es zu einer unangenehmen Situation kommen, wenn das Statement das Standby-System erreicht hat, bevor das Problem erkannt wurde. In diesem Fall würde der Fehler die Daten auf beiden Seiten korrumpieren. Aus diesem Grund kann es sinnvoll sein, eine zeitlich versetzte Standby-Datenbank zu verwenden, die Änderungen erst nach einer bestimmten Zeit verarbeitet.
Vor allem synchrone Replikation kann das System aber auch schwer belasten. Auf der Netzwerkseite kann das Replizieren der Datenbankänderungen einen beachtlichen Teil der verfügbaren Bandbreite beanspruchen. Die Belastung kann hier sehr variieren, je nachdem wie viel in die Datenbank geschrieben wird. Auch die Query-Performance kann darunter leiden, wenn nach jedem COMMIT gewartet werden muss, bis alle Standby-Instanzen die Änderungen bei sich nachgezogen haben und auf einem synchronen Stand sind. Dies ist zwar bei asynchronen Setups nicht der Fall, jedoch sollte man bedenken, dass dort die Standby-Datenbank gegebenenfalls keinen aktuellen Datenstand bereitstellt und zeitlich zurückliegt. Das wiederum kann auf Seiten der Applikation zu Ungereimtheiten und Problemen führen.
Oracle bietet hier als Feature den Oracle RAC (Oracle Real Application Cluster [5] ), der sowohl Connection Pooling und Failover als auch Loadbalancing im Cluster-Umfeld ermöglicht. Oracle Active Data Guard [6] ist ebenso weit verbreitet.
Bei PostgreSQL kann man ein physisches Backup unter anderem via
»pg_basebackup«
(ab Version 9.1.X) herstellen und auch eine Standby-Datenbank sowie eine Streaming-Replication damit einrichten
[7]
. Mit einer Middleware wie PgBouncer
[8]
oder Pgpool-II
[9]
ist auch Connection Pooling/Failover möglich. Für Multimaster- und Multislave-Systeme können hier Tools wie Bucardo
[10]
oder Postgres-XC
[11]
verwendet werden. MySQL bietet unter anderem im Enterprise-Umfeld MySQL-Replication
[12]
als auch MySQL-Cluster
[13]
. Eine Alternative wäre hier der Tungsten Replicator
[14]
. Zudem kann man auch auf Percona und deren Percona XtraDB Cluster (Dropin-Replacement zu InnoDB/MySQL
[15]
) samt Percona XtraBackup ausweichen.
Ähnliche Artikel
-
PGHoard erlaubt PostgreSQL-Backup in Object Stores
Das frei verfügbare Tool unterstützt Object-Storage-Lösungen wie Ceph, Swift und diverse Cloud-Anbieter.
- Asynchrone Replikation in PostgreSQL 9
-
Hochverfügbarkeit und Replikation für PostgreSQL

-
EnterpriseDB Postgres

-
Oracle Database 12c: Cloud Computing mit Multitenant-Architektur

Konfigurationsmanagement

Themen


