
Es geht auch anders
Besser wäre es, nicht innerhalb des DBI-Treibers auf die Datenbank zu warten. Stattdessen sollte man die Operation dort nur initiieren und so die Probleme mit der Signal-Behandlung umgehen. Gesucht ist außerdem ein Merkmal, das anzeigt, ob die Operation beendet ist oder nicht. Am besten wäre es, wenn man dieses nicht regelmäßig abfragen müsste, sondern zu sinnvollen Zeiten eine Aufforderung dazu bekäme. All das lässt sich mit
»DBD::Pg«
implementieren.
Listing 4
zeigt das Resultat. Zeile 5 importiert die Konstante
»PG_ASYNC«
und übergibt sie in Zeile 22 gemeinsam mit dem SQL-Kommando an den Treiber. Damit wird das Verhalten des folgenden Execute-Befehls so geändert, dass er nicht auf das Ende der Anweisung in der Datenbank wartet. Es liegt dann in der Verantwortung des Programms, mit
»$dbh->pg_ready«
regelmäßig zu prüfen, ob die Anfrage schon fertig ist, und gegebenenfalls das Ergebnis zu lesen.
Listing 4
burn2.pl
Als ich zum ersten Mal von dieser Möglichkeit erfuhr, vermutete ich, dass sich damit auch mehrere SQL-Kommandos parallel auf einer Datenbankverbindung ausführen lassen. Das ist aber leider nicht so: Jeder Datenbankprozess kann immer nur eine SQL-Anweisung zu einer Zeit ausführen. Neben
»PG_ASYNC«
gibt es zwei weitere Konstanten in diesem Zusammenhang. Mit
»PG_ASYNC«
kehrt
»execute«
sofort mit einem Fehler zurück, wenn man eine zweite Anweisung ausführen will, während die erste noch läuft.
Abbildung 2
zeigt den Effekt. Es werden zwei Statements vorbereitet. Das erste soll eine Sekunde schlafen, das zweite zwei Sekunden. Der komplette Aufruf dauert nur eine Sekunde, dann erscheint eine Fehlermeldung. Also wurde nur das erste Statement ausgeführt.
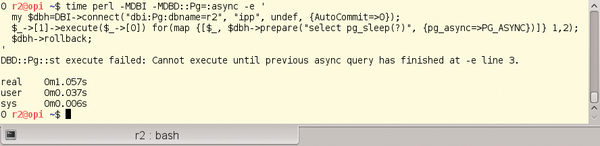 Abbildung 2: Mit dem Flag PG_ASYNC darf das Skript zu einem Zeitpunkt nur eine SQL-Anweisung ausführen.
Abbildung 2: Mit dem Flag PG_ASYNC darf das Skript zu einem Zeitpunkt nur eine SQL-Anweisung ausführen.
Der Schlüssel
»pg_async«
in dem Hash, der an
»prepare«
übergeben wird, ist ein Bitfeld.
»PG_ASYNC«
kann also mit einer der beiden anderen Konstanten modifiziert werden. Übergibt man
»PG_ASYNC | PG_OLDQUERY_CANCEL«
oder
»PG_ASYNC + PG_OLDQUERY_CANCEL«
, wird das gerade laufende Kommando abgebrochen und das neue gestartet. Das Beispiel in
Abbildung 3
dauert zwei Sekunden. Es wird also nur das zweite Statement ausgeführt.
 Abbildung 3: Mit PG_ASYNC + PG_OLDQUERY_CANCEL bricht ein Skript die alte Abfrage ab, um eine neue zu starten.
Abbildung 3: Mit PG_ASYNC + PG_OLDQUERY_CANCEL bricht ein Skript die alte Abfrage ab, um eine neue zu starten.
Mit
»PG_OLDQUERY_WAIT«
wird auf das Ende der gerade laufenden Anweisung gewartet, bevor die nächste startet. Der Befehl in
Abbildung 4
braucht daher drei Sekunden.
 Abbildung 4: Mit PG_ASYNC + PG_OLDQUERY_WAIT wartet ein Perl-Skript das Ende der ersten Abfrage ab.
Abbildung 4: Mit PG_ASYNC + PG_OLDQUERY_WAIT wartet ein Perl-Skript das Ende der ersten Abfrage ab.
Doch zurück zum CGI-Programm. Eine Frage ist nämlich noch offen. Wann ist ein günstiger Zeitpunkt, die
»pg_ready«
-Funktion zu benutzen? In einer Schleife immer und immer wieder? Das würde funktionieren, wäre aber eine enorme Verschwendung von CPU-Zeit. Um dem zu begegnen, könnte man in der Schleife eine Weile schlafen (siehe das Beispiel zu
»pg_ready«
in der
»DBD::Pg«
-Dokumentation). Damit bremst man aber das Programm unnötig aus.
Lösungsansatz
Der richtige Weg ist folgender. Das Medium für den Datenaustausch zwischen
»DBD::Pg«
und der Datenbank ist eine TCP-Verbindung. Wenn die Datenbank mit der Bearbeitung fertig ist, sendet sie normalerweise Daten zum Client. Also wartet man auf I/O-Aktivität des Socket und ruft
»pg_ready«
jedes Mal auf, wenn etwas passiert. Den Socket stellt der Treiber sinnvollerweise in
»$dbh->{pg_socket}«
bereit. Achtung: Dabei handelt es sich nicht um ein Filehandle, sondern um einen Dateideskriptor.
Zeile 25 erzeugt ein
»IO::Select«
-Objekt. Das Skript wartet mit
»$sel->can_read«
(Zeile 26), bis Daten bei der Verbindung ankommen und ruft anschließend
»pg_ready«
auf. Sollte die Funktion "falsch" zurückgeben, wartet das Programm einfach weiter. Der Code geht an dieser Stelle davon aus, dass der Socket nach dem
»pg_ready«
-Aufruf nicht mehr lesbar ist. Ich bin mir nicht sicher, ob das immer gewährleistet ist. Bei meinen Experimenten wurde der Zyklus nie durchlaufen. Das heißt, als die Daten ankamen, lag das Ergebnis vor.
Die Zeilen 29 und 35 werten
»$dbh->{pg_async_status}«
aus. Der Wert 1 zeigt an, dass ein asynchrones SQL-Kommando aktiv ist; 0 bedeutet, das letzte Kommando war synchron, während -1 dafür steht, dass das letzte Kommando asynchron war und abgebrochen wurde.
Wurde das Kommando nicht abgebrochen, läuft
»$dbh->pg_result«
ab. Diese Funktion gibt genau dasselbe zurück wie
»$dbh->execute«
für synchrone Kommandos. Der Rückgabewert wird hier ignoriert. Der Aufruf selbst ist aber nötig, sonst liefert
»fetchrow_arrayref«
kein Ergebnis. Insbesondere für Updates der Datenbank ist der Rückgabewert oft wichtig.
Was passiert nun, wenn Apache das SIGTERM-Signal schickt, während das Programm in
»$sel->can_read«
in Zeile 26 (genauer dem zugrunde liegenden Systemaufruf
»select«
) wartet? Der Systemaufruf wird abgebrochen. Noch bevor
»$sel->can_read«
zurückkehrt, erreicht die Ausführung einen sicheren Punkt, an dem Signal-Handler aufgerufen werden können. Der Signal-Handler stellt fest, dass eine asynchrone Anfrage aktiv ist und ruft daher
»$dbh->pg_cancel«
auf. Diese Funktion teilt dem Datenbankprozess mit, dass die aktuelle Abfrage abzubrechen ist, und wartet auf Bestätigung.
Nun kehrt
»$sel->can_read«
zurück. Der folgende
»pg_ready«
-Aufruf liefert "wahr". Die Abfrage wurde aber abgebrochen. Daher landet die Ausführung in Zeile 36.
Ähnliche Artikel
-
PostgreSQL Notifications mit Perl

-
Monitoring mit Signal-Messenger

- Linux-Virtualisierung ohne Qemu
-
Textbasierte GUI mit Perl

-
ADMIN-Tipp: Dateiänderungen überwachen
Die Inotify-Schnittstelle des Linux-Kernels erlaubt es, Dateien und Verzeichnisse im Blick zu behalten. Mit der Python-API lassen sich dafür eigene Skripte schreiben.
Konfigurationsmanagement

Themen


