
Shared-Nothing-Storage
Die Linux-Replikationslösung DRBD nutzt einen anderen Ansatz als das SAN. Bei DRBD ist ein Datensatz stets zweimal vorhanden, nämlich einmal auf dem einen Knoten eines Zweiknoten-Clusters und einmal auf dem anderen Knoten. Im Normalbetrieb sorgt DRBD dafür, dass die Datenbestände der beiden Storagelaufwerke immer gleichbleiben, indem es sich zwischen Speichermedium und Dateisystem klemmt und Änderungen von einem Server sofort auf den anderen repliziert. Weil es so immer zwei voneinander völlig unabhängige Datensätze gibt, spricht man bei DRBD vom "Shared Nothing Storage". Im Gegensatz dazu sind klassische SANs sogenannte "Shared Everything Storages".
Was tut DRBD genau? Die Erklärung des Funktionsprinzips von DRBD steckt bereits im Namen, denn DRBD ist das Distributed Replicated Block Device. Der Begriff erklärt sich am besten, wenn man das sprichwörtliche Pferd von hinten aufzäumt:
Block Device verkörpert DRBDs Eigenschaft, Teil des Block Device Layers des Linux-Kernels zu sein ( Abbildung 1 ). Gemeint ist ein Universum von Treibern, die die blockbasierte Speicherfunktion gemein haben. Sämtliche Treiber des Block Device Layers können die gleiche Infrastruktur verwenden. Klassische Block-Device-Treiber sind die Treiber für Festplatten oder auch USB-Sticks; aber auch LVM und Mdraid gehören zu diesem Layer. Treiber dieses Layers lassen sich nahtlos über- oder untereinander stapeln, ohne dabei Performance-Einbußen zu erleiden. Eine DRBD-Resource sieht aus Systemsicht aus wie jede andere Festplatte auch; sie kann auf einem Software-RAID liegen oder auf einem LVM, das seinerseits auf einem Software-RAID liegt. Hieraus ergibt sich die Tatsache, dass DRBD "applikationsagnostisch" ist. Weil im täglichen Gebrauch auf einem DRBD-Laufwerk genauso ein Dateisystem zu finden sein sollte wie auf einem LVM, merken Programme keinen Unterschied.
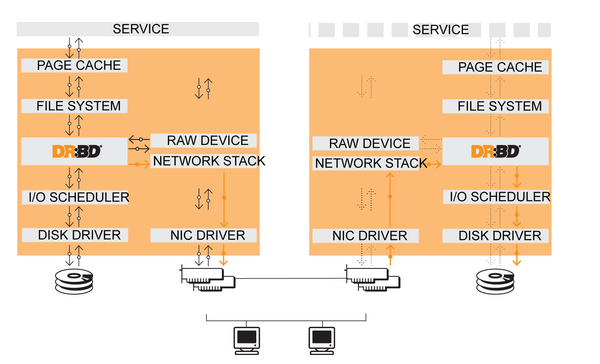 Abbildung 1: So integriert sich DRBD in den Linux-Kernel und realisiert die Replikation.
Abbildung 1: So integriert sich DRBD in den Linux-Kernel und realisiert die Replikation.
Replicated meint im DRBD-Kontext, dass jeder Schreibvorgang, der auf einem DRBD-Laufwerk abgewickelt wird, immer zweimal passiert.
Distributed erklärt, wo der doppelte Schreibvorgang passiert – nämlich an unterschiedlichen Stellen. Die Abbildung 1 vermittelt einen guten Eindruck davon, wo DRBD im Linux-Kern ansetzt.
Wie DRBD funktioniert
Eine typische DRBD-Ressource umfasst zwei Server. Auf beiden Servern nimmt der DRBD-Treiber nach dem Start ein Storage-Device exklusiv in Beschlag. Es heißt im DRBD-Kontext Backing Device. Gleichzeitig baut er eine Netzwerkverbindung mittels TCP/IP zum anderen DRBD-Server auf. Im Cluster gibt es zwei Rollen: Ein Server hat die Primary-Rolle und der andere hat die Secondary-Rolle. Ausschließlich auf dem primären DRBD-Knoten ist es möglich, die DRBD-Resource lesend und schreibend zu nutzen.
Im normalen Betrieb ist DRBD darauf ausgelegt, den Inhalt des Storage vom primären Knoten mit dem des sekundären Knoten identisch zu halten. Dazu wird jeder Schreibzugriff auf das lokale Storage-Device automatisch auch über den TCP/IP-Stack auf das andere Device im sekundären Knoten repliziert. Sobald sich auf dem primären Knoten ein Block auf der Platte ändert, kopiert DRBD den Block auch auf den sekundären Server. Ist der Block heil am sekundären Server angekommen und dort ebenfalls auf die Platte geschrieben, gilt der Schreibvorgang als abgeschlossen. Dieser Prozess läuft im Hintergrund permanent. Er heißt Replikation.
Verlieren die beiden DRBD-Clusterknoten ihre Verbindung, setzen diverse Prozesse ein. Auf dem primären Server legt DRBD nun eine Bitmap an, in der er alle Blöcke vermerkt, die sich zwischenzeitlich ändern. Ist der primäre Clusterknoten ausgefallen, braucht DRBD Unterstützung von einem Clustermanager wie Pacemaker (siehe den Beitrag zum Thema auf S. 68 in diesem Heft). Dieser macht dann aus dem vormals sekundären DRBD ein primäres und legt auf diesem eine Bitmap an. Kommt der andere Clusterknoten zurück, kopiert DRBD alle in der erwähnten Bitmap verzeichneten Blöcke vom aktuellen primären Knoten auf den zurückgekehrten anderen Knoten. Der Prozess dauert so lange, bis alle Clusterknoten wieder exakt den gleichen Datenbestand haben. Der Vorgang heißt Resynchronisation. Er findet nur statt, wenn die beiden DRBD-Clusterknoten ihre Verbindung nach einem Ausfall wiederaufbauen.
Replikation und Resynchronisation passieren gleichzeitig, doch kommt der Replikation das größere Gewicht zu. Verändert sich bei der Replikation ein Block erneut, der bereits in der Bitmap steht, weil er noch resynchronisiert werden muss, so kopiert DRBD den betroffenen Block direkt und streicht ihn aus der Bitmap.
Ähnliche Artikel




Konfigurationsmanagement

Themen


