Traffic Shaping: Niedrige Latenz bei voller Bandbreite mit Linux

Schnell sein, Held sein

Auch die Besitzer eines schnellen oder gar symmetrischen DSL-Anschlusses kennen den Effekt: Während die Bürokollegen dicke E-Mails verschicken, ISO-Images runterladen und Videos schauen, gerät das eigene VoIP-Telefonat zur von Aussetzern und akustischen Artefakten geprägten Tortur – dagegen hilft nur Traffic Shaping [1] . Damit lassen sich die Latenzzeiten zeitkritischer Übertragungen auf ein Drittel bis ein Sechstel verringern. Das Bandbreitenmanagement hilft auch die Reaktionszeit von interaktiven SSH-, Rdesktop und ähnlichen Verbindung deutlich zu optimieren.
Tabelle 1 vergleicht die Ping-Zeiten auf einer symmetrischen 2-MBit/s-Internetstandleitung zwischen einem Debian Lenny ohne Traffic Shaping und der später in diesem Artikel vorgestellten Shaping-Lösung Trafficcontrol-inetgw. Die Nutzdatenrate lag während der Messung jeweils bei knapp 1,9 MBit/s, Gegenstelle war [www.google.de] .

Der beliebte Wondershaper [2] dient hier funktionell und in Sachen Performance als Referenz. Er verwendet für den Paketversand eine CBQ-QDisc [3] mit drei Warteschlangen. Dies erfüllt zwei Aufgaben:
- Es verhindert einen Stau im Modem, der normalerweise deshalb entsteht, weil DSL-Router und Kabelmodems Datenpakete wesentlich schneller aus dem LAN empfangen als diese sich ins Internet versenden lassen. Der Router verwaltet daher eine manchmal mehrere Sekunden lange Warteschlange, die sich der Kontrolle des Linux-Kernels entzieht ( Abbildung 1 ). Die CBQ-QDisc dagegen gestattet den Paketversand in Richtung Router nur, solange dort eine bestimmte Bandbreite unterschritten ist. Die hat der Administrator so zu konfigurieren, dass sich gerade keine Warteschlange aufbaut. (Der Kasten "Glossar" und [4] helfen beim Navigieren durch die etwas komplizierte Begriffswelt.)
Glossar
Ingress: Eingehender Datenstrom.
Egress: Ausgehende Datenstrom.
Classifying: Pakete mit Filtern priorisieren und einer Warteschlange zuweisen [7] .
Shaping: Hält Pakete in einer Warteschlange zurück, sobald der ausgehende Datenstrom (Egress) eine bestimmte Bandbreite überschreitet. Läuft die Warteschlange voll, werden neue Pakete verworfen.
QDisc: Im Linux-Kernel gibt es verschiedene Queueing Disciplines, also Regeln, nach denen ausgehende Pakete Schlange stehen. Einige QDiscs sind hierarchisch aufgebaut und dürfen weitere Klassen und QDiscs enthalten. Man spricht dann von "classful".
CBQ: Das Class Based Queueing ist einer von mehreren Mechanismen, um priorisierte Pakete abzuarbeiten. Dazu gibt es mehrere unterschiedlich priorisierte Queues, die ein Weighted-Round-Robin-Prozess (WRR) abklappert. Zum Beispiel versendet er zehn Pakete von Queue 1, anschließend fünf Pakete von Queue 2, eines von Queue 3 und dann wieder zehn von Queue 1 und so weiter [3] .
HTB: Die seit Kernel 2.4.20 fest in den Kernel integriert Discipline "Hierarchical Token Bucket" funktioniert ähnlich wie Class Based Queueing, aber mit einem Token-Bucket-Filter: Wie CBQ teilt HTB die verfügbare Bandbreite auf mehrere Klassen auf und garantiert jeder Klasse auch bei starker Auslastung eine gewisse Bandbreite. Überschüssige Bandbreiten verteilt HTB auf die anderen Klassen [10] .
Policing: Verwirft bestimmte Ingress-Pakete.
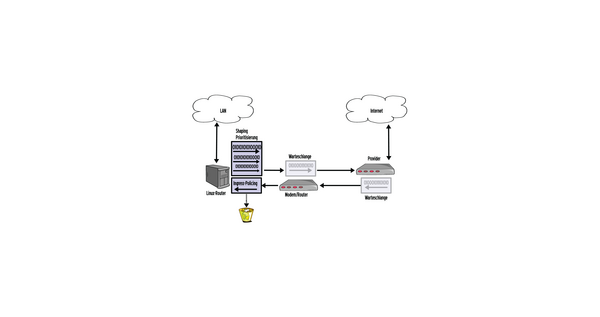 Abbildung 1: Beim Up- und Download bilden sich an mehreren Stellen Warteschlangen. Wer die Reaktionszeit optimieren will, sollten ihr Entstehen beim Provider und im eigenen DSL-Modem oder -Router vermeiden. Der Linux-Kernel hilft mit Shaping und Policing dabei.
Abbildung 1: Beim Up- und Download bilden sich an mehreren Stellen Warteschlangen. Wer die Reaktionszeit optimieren will, sollten ihr Entstehen beim Provider und im eigenen DSL-Modem oder -Router vermeiden. Der Linux-Kernel hilft mit Shaping und Policing dabei.
- Zum anderen kann der Kernel Pakete auf die drei Warteschlangen den gewünschten Antwortzeiten entsprechend verteilen. Die CBQ-QDisc arbeitet die Warteschlangen nach ihrer Priorität ab und bevorzugt Latenz-empfindliche Pakete damit deutlich. Das hat mehrere Vorteile. So kommen ACK-Pakete schneller auf den Weg, wodurch ein Upload einen Download weniger ausbremst. Auch SSH- und ICMP-Pakete erfahren bevorzugte Abfertigung, weitere Protokolle lassen sich leicht ergänzen. Sinnvoll ist das natürlich nur, solange keine zusätzliche Warteschlange im Modem existiert.
Für eingehende Datenpakete bietet der Kernel leider deutlich weniger Möglichkeiten als für den Versand – warum auch, schließlich ergibt es keinen Sinn, ein gerade eingetroffenes Paket erst mal in einer Warteschlange zu deponieren. Eine Warteschlange bildet sich im Downstream trotzdem: beim Provider. Während eines Downloads treffen dort Pakete nämlich deutlich schneller ein, als sie sich an den Kunden weiterleiten lassen.
Um den Stau in der Warteschlange beim Provider zu minimieren, bleibt dem Kunden nur, diesen um einen langsameren Versand zu bitten. Dazu bietet der Linux-Kernel die Ingress-QDisc [5] . Sie erlaubt es, nur bestimmte Pakete zu verwerfen. Der Absender einer TCP-Verbindung schickt das Paket daraufhin erneut und drosselt die Transferrate.
Auch der Wondershaper benutzt die Ingress-QDisc, um Pakete zu verwerfen, sobald der eingehende Datenstrom eine vom Administrator gewählte maximale Bandbreite überschreitet. Leider verwirft die Ingress-QDiscs so gelegentlich auch ACK-Pakete eines Uploads oder andere empfindliche Pakete, was die Latenzen für interaktive Anwendungen erhöht.
Einige noch wenig bekannte Optionen im TC-Subsystem des Kernels versprechen jedoch Hilfe, um Pakete differenzierter zu behandeln, als Wondershaper und andere Traffic-Shaping-Software das tun. Das jetzt vorstellte Trafficcontrol-inetgw [6] ist als Komplettlösung zur Latenzoptimierung auf Internetgateways mit dynamischer Overhead-Berechnung und differenziertem Ingress-Policing ausgelegt.
Dynamischer Overhead
Um die Warteschlangen im lokalem Modem und beim Provider zu vermeiden, muss der Linux-Kernel die übertragenen Paketgrößen inklusive aller Overheads kennen. Daraus ergibt sich die Bandbreite, die wirklich über den Internetzugang läuft. Beim Versand eines TCP-Pakets über DSL kommen zu den Nutzdaten die Header für TCP, IP, PPP, PPPoE, Ethernet und ATM. Besonders trickreich ist, dass ein Ethernet-Paket mindestens 64 Bytes groß sein muss und eine ATM-Zelle immer genau 53 Bytes umfasst. Bei ATM gibt es noch eine Besonderheit. Die letzte für ein Ethernet-Paket verwendete Zelle fasst nur 40 Bytes Nutzdaten, alle vorher 48. Das Modem füllt die fehlenden Bytes mit Nullen auf. Tabelle 2 verdeutlicht die quantitativen Zusammenhänge.
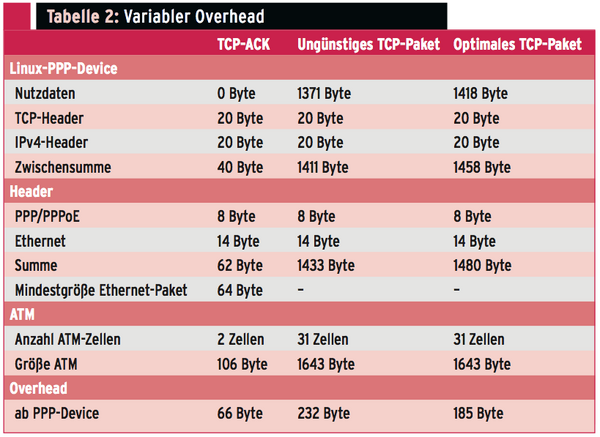
Der Overhead eines Datenpakets ist also nicht konstant, sondern abhängig von der Nutzdatenmenge. Erst neuere Linux-Kernel zusammen mit neueren IProute-Versionen können die Rohdatenmenge im ATM-Netz korrekt berechnen (
[8]
,
[9]
) – vorausgesetzt man verwendet eine QDisc, die das unterstützt, etwa Hierarchical Token Bucket (HTB,
[10]
). Dort gibt es den neuen Parameter
»linklay«
, der die ATM-Rohdatenmenge korrekt berechnet. Für die Root-HTB-Klasse zum Beispiel sieht das so aus:
tc class add dev ppp0 parent 1: classid 1:1htb rate 205kbit ceil 205kbit linklay atm
Auch beim Ingress-Policing (Empfang) ist der Parameter erlaubt:
tc filter add dev ppp0 parent ffff:protocol ip prio 110 u32 match ip src0.0.0.0/0 flowid :1 police rate 1710kbitburst 6k linklay atm conform-exceedcontinue/ok
Außer ATM unterstützt
»linklay«
zurzeit Ethernet als Übertragungsschicht.
Auch mit betagtem Kernel
Wenn die gewünschte QDisc
»linklay«
nicht unterstützt, der Kernel zu alt ist oder gar eine exotische Übertragungsschicht im Spiel ist, gelingt es mit zwei Parametern dem Kernel oft, trotzdem die Rohdatenmenge zu berechnen:
-
»
mpu« gibt die minimale Größe in Bytes an, die ein IP-Paket beim Übertragen hat. Für einen DSL-Anschluss sind das 106 (zwei ATM-Zellen). -
»
overhead« gibt die Byte-Anzahl an, die zur Paketgröße des verwendeten Linux-Netzwerkdevice zu addieren ist. Für den PPP- und Ethernet-Header müsste der Wert 22 Bytes sein. Der Autor hat jedoch experimentell ermittelt, dass auf einem ADSL-Anschluss »14« eine kürzere Antwortzeit erzielt.
Hier ein Beispiel für eine Root-HTB-Klasse mit beiden Parametern:
tc class add dev ppp0 parent 1: classid 1:1htb rate 205kbit ceil 205kbit mpu 106overhead 14
Versuche zeigten, dass
»mpu«
und
»overhead«
mit
»linklay atm«
zu kombinieren die Reaktionszeit tendenziell erhöht.
Ähnliche Artikel




Konfigurationsmanagement

Themen


