Monitoring außerhalb der Datenbank
Gerade unter Linux stehen eine Vielzahl von Kommandozeilentools zur Verfügung, um die aktuelle Auslastung von Speicher, CPU und Disk-Storage zu analysieren. Das bereits angesprochene bekannte Top bietet viele Informationen auf einen Blick und gibt schnell Auskunft über die aktuelle Last der CPU, den Verbrauch von Hauptspeicher oder die Anzahl aktiver Prozesse.
Um sich die Auslastung des Hauptspeichers etwas genauer anzusehen, sollte man einen Blick auf »vmstat« werfen (Abbildung 3). Wie der Name bereits erahnen lässt, gibt es detailliert Aufschluss über die aktuelle Speicherverwendung und lässt auch Bottlenecks sehr leicht erkennen. Gerade die Spalten »si« und »so« sollten nur ausnahmsweise einen anderen Wert als 0 haben. Ist dies nicht der Fall, deutet es auf Swapping hin. Entweder kann man durch Aufrüstung des Hauptspeichers schnellstmöglich Abhilfe schaffen oder man muss kurzfristig den bereitgestellten Platz für die Datenbank-Puffer verringern. Da der Disk-Storage die langsamste Komponente des Systems darstellt, ist er auch Problemursache Nummer 1. Zwar lässt sich die Anzahl der Write- und vor allem Read-Operationen durch Tuning von Statements und Optimierung des Datenbankschemas optimieren, dennoch sind die Platten der häufigste Bottleneck.
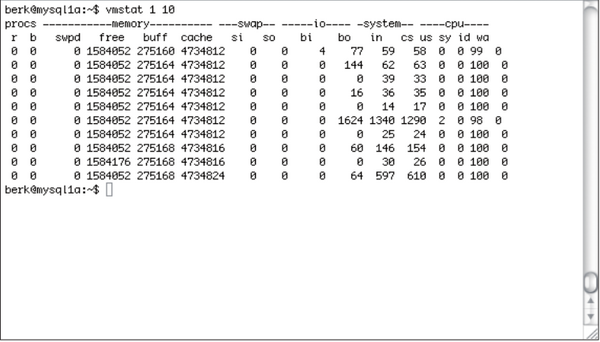 Abbildung 3: Vmstat gibt Aufschluss über die Verwendung des Speichers. Der sollte stets so reichlich bemessen sein, dass das Betriebssystem keine Speicherbereiche auf die Festplatte auslagern muss.
Abbildung 3: Vmstat gibt Aufschluss über die Verwendung des Speichers. Der sollte stets so reichlich bemessen sein, dass das Betriebssystem keine Speicherbereiche auf die Festplatte auslagern muss.
Ein Blick auf den InnoDB-Monitor gibt häufig Aufschluss über die zu schreibenden Informationen und den damit verbunden I/O-Engpass. Sobald das Betriebssystem keine Möglichkeit findet, anstehende Writes an das Storage-Subsystem abzutreten, kann es innerhalb kürzester Zeit zu Einbrüchen bei Latenz und Durchsatz kommen. Der wachsende I/O-Buffer blockiert intern sowohl CPU als auch LAN und endet in synchronem Disk-I/O. Bei anhaltender Auslastung kann das System somit vollständig stehen bleiben. Neben bekannten Tools wie »sar« bietet hier das Kommando »iostat« gute Einblicke (Abbildung 4) in den aktuellen I/O-Status des Systems und lässt Engpässe auch bei einzelnen Devices leicht erkennen. Bei der Ausführung mit dem Parameter ‑x (extended) lassen die Spalten »svctm« und »%util« auf einen Blick die Überlastung erkennen. Kurzfristige Abhilfe kann die Verlagerung des Filesystems auf eine andere RAID-LUN oder die Reorganisaton des Plattensubsystems schaffen.
 Abbildung 4: Iostat verrät die Engpässe im Platten-Subssystem leicht. Hier sind die häufigsten Bottlenecks zu finden.
Abbildung 4: Iostat verrät die Engpässe im Platten-Subssystem leicht. Hier sind die häufigsten Bottlenecks zu finden.
Übersicht behalten
MySQL liefert alle zur Bewertung des Systemzustands nötigen Counter und Informationen. Zwar ist nicht immer ein so detailierter Blick auf das Datenbanksystem tatsächlich wichtig, doch sollte dem Administrator die Bedeutung der einzelnen Werte geläufig sein – nur so kann er sie interpretieren. Um einen qualifizierten Rückschluss ziehen zu können, reicht es außerdem nicht, nur die zahlreichen Hit-Rates und Counter zu betrachten, sondern es ist immer auch ein erweiterter Blick auf die eigentliche Aufgabenstellung und auf die aktuelle Lastsituation notwendig. (jcb/ofr)
Infos
[1] Status-Variable: http://dev.mysql.com/doc/refman/5.1/de/server‑status‑variables.html
[2] Query-Cache: http://dev.mysql.com/tech‑resources/articles/mysql‑query‑cache.html
[3] Slave-States: http://dev.mysql.com/doc/refman/5.1/de/slave‑io‑thread‑states.html
[4] InnoDB-Monitor: http://dev.mysql.com/doc/refman/5.1/de/innodb‑monitor.html
[5] Innotop-Documentation: http://innotop.sourceforge.net/innotop.html
Ähnliche Artikel
-
MySQL-Replikation mit GTIDs

- Maatkit für MySQL
-
MySQL 5.7 bringt massive Verbesserungen

-
MySQL InnoDB Cluster veröffentlicht
MySQL veröffentlicht ein Paket zum hochverfügbaren Cluster-Betrieb mit Gruppenreplikation.
-
Replikation in MySQL-Datenbanken

MySQL-Replikation mit GTIDs
Konfigurationsmanagement

Themen


